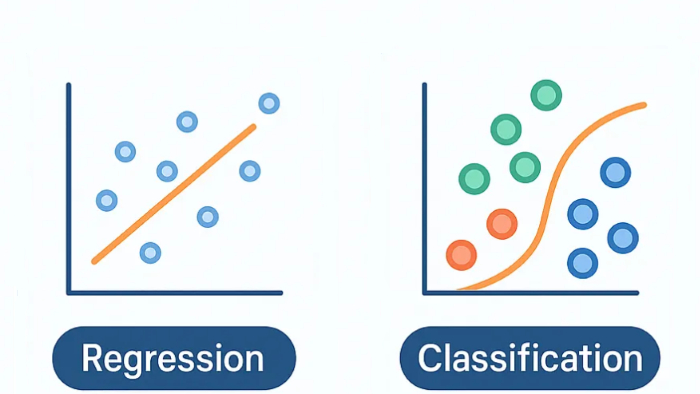
در این مقاله، اختلافهای بین رگرسیون (Regression) و کلاسبندی (Classification) در مبحث یادگیری ماشین (Machine Learning) توضیح داده میشود و میزان اهمیت هر یک برای دانشمندان داده و افراد مرتبط با فناوری روز، بررسی میشود. این دو روش برای مدلسازی پیشبینی کننده و حل مسائل خاص، استفاده میشوند. هر دو ابزار رگرسیون و کلاسبندی، تحت عنوان الگوریتمهای یادگیری با ناظر (Supervised Learning) شناخته میشوند و با مجموعه دادههای برچسب گذاری شده (Labeled) کار میکنند ولی نحوه رویکرد متفاوت آنها با مسائل یادگیری ماشین، نقطه تمایز و واگرایی آنها نسبت به هم است. در اینجا میخواهیم یک بررسی دقیق و با جزئیات از ویژگیها، کاربردها، مزایا و چالشهای آنها به منظور تجهیز متخصصین به دانش لازم برای استفاده موثر از این دو ابزار در مسائل مرتبط با علوم داده، داشته باشیم.
رگرسیون چیست؟
رگرسیون میزان همبستگی بین متغیر وابسته و متغیرهای مستقل را مییابد و بر همین اساس، الگوریتمهای رگرسیون، مقادیر پیوسته (Continuous) را به کمک ورودی ارائه شده به مدل، پیشبینی میکنند. یک الگوریتم یادگیری با ناظر از مقادیر واقعی برای پیشبینی دادههای کمّی (Quantitative) همچون درآمد، قد، وزن، امتیاز یا احتمال رخداد یک پدیده، استفاده میکنند. به عبارت دیگر، کار اصلی الگوریتم رگرسیون، یافتن تابع نگاشتی است که میتواند رابطه بین متغیرهای ورودی، \( x \) و متغیر پیوسته خروجی، \( y \) را توصیف کند. مهندسین یادگیری ماشین و علوم داده، اغلب از الگوریتمهای رگرسیون برای کار بر روی مجموعه دادههای برچسب گذاری شده در حین تطبیق مدلهای تخمینی مختلف، استفاده میکنند.
مفاهیم کلیدی در رگرسیون
یادگیری با ناظر: رگرسیون یک نوع از یادگیری با ناظر اس که شامل آموزش مدل توسط داده برچسب گذاری شده است که در آن متغیر هدف معلوم است. این روش به مدل این امکان را میدهد که رابطه بین شاخصهای ورودی (متغیرهای مستقل) و متغیر هدف (متغیر وابسته) را یاد بگیرد.
– متغیر هدف پیوسته: برخلاف کلاسبندی که برچسبهای گسسته یا کلاسها را پیشبینی میکند، رگرسیون یک مقدار عددی پیوسته را باید پیشبینی کند. برای مثال، پیشبینی قیمت خانهها، قیمت سهام، دما یا سود فروش شرکتها، همگی مسائل رگرسیون هستند که در آنها متغیر هدف یک مقدار پیوسته است.
کلاسبندی چیست؟
کلاسبندی فرآیندی است که در آن یک مدل یا تابع، داده را با کمک شاخصهای مستقل، به مقادیر گسسته یا کلاسهای چندگانه دستهبندی کرده و از هم جدا میکند. تابع نگاشت نهایی از یک نوع قاعده اگر-آنگاه (If-Then rule) حاصل میشود. زمانیکه از یک الگوریتم کلاسبندی استفاده میکنیم، در واقع برنامه رایانهای مورد نظر، به کمک داده آموزشی یاد میگیرد که داده را چگونه به دستههای مختلف دستهبندی و کلاسبندی کند. الگوریتمهای کلاسبندی، تابع نگاشت برای تطبیق ورودی \( x \) به خروجی گسسته \( y \) را پیدا میکنند. مقادیر هدفی همچون اسپم یا غیراسپم بودن یک ایمیل، آری یا خیر بودن پاسخ به یک سوال خاص، صحیح یا غلط بودن یک فرضیه، از جمله مقادیری است که توسط آن پیشبینی میشوند. یک مثال از برچسب گسسته برای داده، امکان بازدید یک بازیگر از یک مرکز خرید برای ارتقا اعتبار فروشگاه خاص بر اساس سابقه رخدادهای مرتبط است. این برچسب میتواند آری یا خیر باشد.
مفاهیم کلیدی در کلاسبندی
یادگیری با ناظر: کلاسبندی یک نوع از یادگیری با ناظر است که در آن مدل توسط مجموعه داده برچسب گذاری شده، آموزش میبیند. این بدان معنی است که داده مورد استفاده برای آموزش، شامل هر دو مقدار شاخصهای ورودی (متغیرهای مستقل) و برچسبهای هدف مورد نظر (متغیر وابسته) است.
متغیر هدف دستهای (Categorical): متغیر هدف در کلاسبندی، دستهای یا متعلق به یک دسته و گروه خاص است بدین معنی که شامل برچسب کلاسهای مختلفی است که دستهها یا کلاسهای مختلفی را نمایندگی میکنند.
انواع رگرسیون
در ادامه، برخی انواع مهم رگرسیون را مرور میکنیم.
رگرسیون خطی (Linear Regression)
این نوع رگرسیون بیشتر ترجیح داده میشود و سادهتر است زیرا معادلات خطی را به مجموعه داده اعمال میکند. استفاده از یک خط راست برای توصیف رابطه بین دو متغیر کمّی، یعنی متغیر مستقل و وابسته، در رگرسیون ساده خطی برای مدلسازی انجام میشود. البته یک متغیر وابسته، میتواند بیش از یک متغیر مستقل را نیز برای توصیف رابطه رگرسیون استفاده کند. این روش در تحلیل بازار، فروش و پیشبینی تقاضا قابل استفاده است. معادله آن در حالت کلی به شکل زیر است:
$$ y = \beta_0+\beta_1 X_1 + \beta_2 X_2 + … + \beta_n X_n + \epsilon $$
رگرسیون چندجملهای (Polynomial Regression)
روش یافتن یا مدل کردن رابطه غیرخطی بین یک متغیر مستقل و وابسته را رگرسیون چندجملهای میگویند. این روش به طور خاص برای مجموعه دادههای با روند منحنیوار استفاده میشود. زمینههای مختلف کاربردی همچون علوم اجتماعی، اقتصاد، بیولوژی، مهندسی و فیزیک از یک تابع چندجملهای برای پیشبینی دقت مدل و پیچیدگی آن استفاده میکنند. در یادگیری ماشین، رگرسیون چندجملهای برای پیشبینی ارزشهای مهم مشتریان، قیمت سهام و املاک استفاه میشود. معادله این روش نیز به شکل زیر است:
$$ y = \beta_0+\beta_1 X^1 + \beta_2 X^2 + … + \beta_n X^n + \epsilon $$
رگرسیون لاجیستیک (Logistic Regression)
این روش که معمولا تحت عنوان مدل logit شناخته میشود، شانس محتمل رخداد یک پدیده را درک میکند. این روش از یک مجموعه داد متشکل از متغیرهای مستقل استفاده میکند و کاربردهایی در تحلیل پیشگویانه و کلاسبندی دارد. معادله این روش به شکل زیر است:
$$ p(X) = \frac{1}{e^{-(\beta_0+\beta_1 X)}} $$
شکل زیر مقایسهای بین این روشها را برای یک مجموعه داده نشان میدهد:
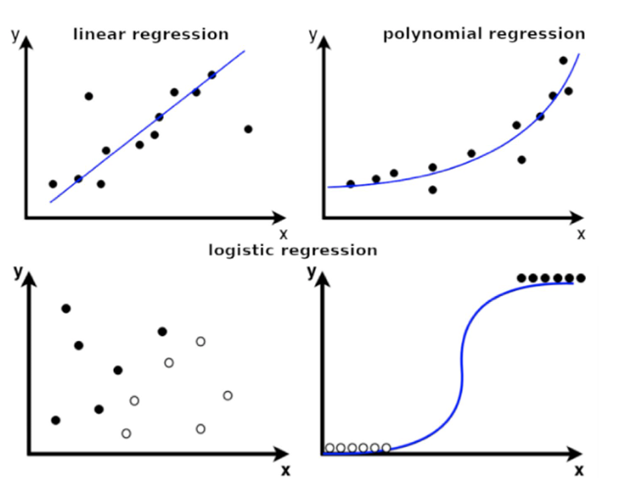
شکل 1- مقایسه روشهای رگرسیون
برخی دیگر از روشهای رگرسیون
رگرسیون درخت تصمیمگیری (Decision Tree): هدف اصل این روش، تقسیم مجموعه داده به زیرمجموعههای کوچکتر است. این زیرمجموعهها به منظور رسم مقدار عددی هر نقطه داده مرتبط با خواست مساله مورد نظر، ایجاد میشوند.
رگرسیون جزء اصلی (Principal Component): این روش رگرسیون به طور گسترده استفاده میشود. در اینجا متغیرهای مستقل زیادی وجود دارند یا به نوعی در داده همخطی چندگانه (Multicolinearity) دیده میشود.
رگرسیون جنگل تصادفی (Random Forest): این روش نیز به طور وسیع در یادگیری ماشین استفاده میشود. در آن از چندین درخت تصمیمگیر برای پیشبینی خروجی استفاده میشود. از مجموعه داده، نقاطی به صورت تصادفی انتخاب میشوند و برای ساخت یک درخت تصمیمگیری توسط الگوریتم مورد نظر، استفاده میشوند.
رگرسیون بردار پشتیبان (Support Vector): این روش رگرسیون، هر دو نوع مساله خطی و غیرخطی را در مدلسازی میتواند حل کند. در اینجا از توابع هسته (Kernel) غیرخطی همچون چندجملهایها برای یافتن یک راهحل بهینه برای مدلهای غیرخطی، استفاده میشود.
انواع کلاسبندی
حال بیایید برخی انواع مهم کلاسبندی را بررسی کنیم.
از دید تعداد کلاسهای قابل دستهبندی، دو نوع کلی کلاسبندی باینری یا دو کلاسه (Binary Classification) و چند کلاسه (Multi-class Classification) داریم. به لحاظ فناوری و روش کلاسبندی نیز روشهای مختلفی وجود دارد که به برخی از مهمترین آنها اشاره میکنیم.
کلاسبندی باینری
زمانیکه داده ورودی متشکل از شاخصهای مختلف که معرف هر نقطه از داده هستند به مدل داده شود و برچسب خروجی معرف یکی از دو برچسب ممکن باشد، کلاسبندی باینری خواهیم داشت. به طور مثال خروجی میتواند جواب بله/خیر (در تشخیص اسپم بودن ایمیل)، مثبت/منفی (در تشخیص بیماری) و غیره باشد.
کلاسبندی چند کلاسه
در یادگیری ماشین، کلاسبندی چند کلاسه، بیش از دو امکان در خروجی را فراهم میکند. انواع این گونه کلاسبندی شامل الگوریتمهای یک در مقابل همه (One vs. All) و چند کلاسه میشود. این نوع کلاسبندی، تکیه بر نوع دو کلاسه ندارد و مجموعه داده را به چند کلاس، طبقهبندی میکند.
برخی روشهای کلاسبندی از منظر الگوریتم
کلاسبندی درخت تصمیمگیری (Decision Tree Classification): این روش، مجموعه داده را بر اساس متغیرهای شاخص آن، به چند بخش تقسیم میکند. مقادیر سطح آستانه این تقسیم، معمولا میانگین یا مُد متغیرهای شاخص در شرایطی که مقدار عددی باشند، هستند.
کلاسبندی K همسایه نزدیک (K-Nearest Neighbor): این نوع کلاسبندی، K همسایه نزدیک به هر نقطه مشاهده شده را پیدا میکند. سپس از این K نقطه برای ارزیابی نسبت حضور متغیر هدف در آن و پیشبینی متغیر هدف کلاس مربوطه با بیشترین نسبت، استفاده میکند.
رگرسیون لاجیستیک (Logistic Regression Classification): این نوع کلاسبندی پیچیده نیست و به همین دلیل به سادگی و با کمترین میزان آموزش قابل اتخاذ است. این روش، احتمال متغیر هدف خروجی مرتبط با ورودی را پیشبینی میکند.
بیزین ساده (Naive Bayes): این کلاسبند، یکی از موثرترین و در عین حال سادهترین الگوریتمها است. این روش بر پایه قضیه بیز (Bayes Theorem) است که نحوه محاسبه احتمال رخداد بر اساس دانش قبلی از شرایط موجود که با رخداد مورد نظر ارتباط پیدا میکند، را توضیح میدهد.
کلاسبندی جنگل تصادفی (Random Forest Classification): جنگل تصادفی تعداد زیادی درخت تصمیمگیری تولید میکند که هر کدام برای احتمال متغیر هدف، مقداری را پیشبینی میکنند. سپس به کمک میانگین احتمالات، نتیجه نهایی مشخص میشود.
ماشین بردار پشتیبان (Support Vector Machine): این الگوریتم، کلاسبند بردار پشتیبان را با یک تغییر جالب که آن را برای تعیین مرزهای تصمیمگیری غیرخطی ایدهآل میسازد، به خدمت میگیرد. این فرآیند بوسیله گسترش فضای متغیرهای شاخص به کمک توابع ویژه که هسته (Kernel) نام دارند، ممکن میشود.
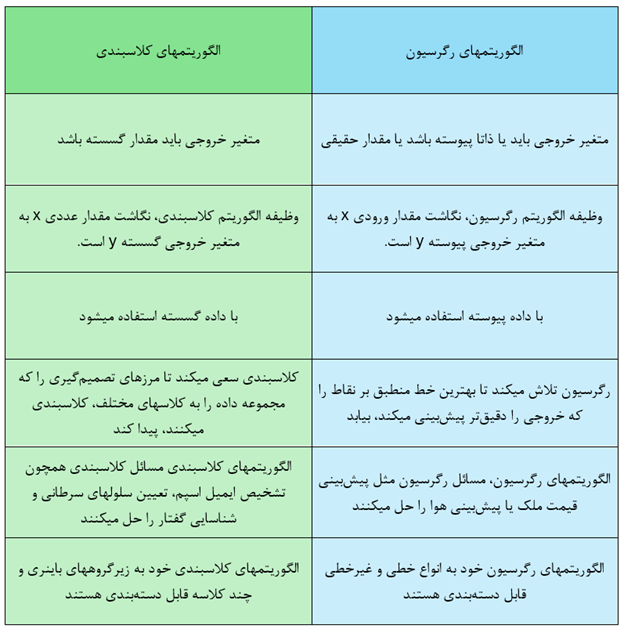
تفاوتهای بین رگرسیون و کلاسبندی
شکل زیر، کلاسبندی را در مقایسه با رگرسیون نمایش میدهد. 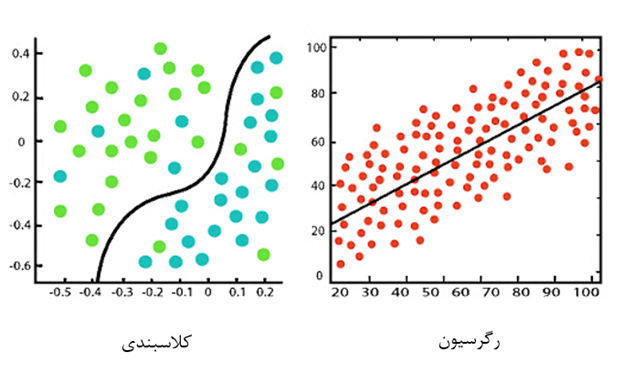
شکل 2- مقایسه رگرسیون و کلاسبندی
در جدول زیر نیز تفاوتهای مشخص بین رگرسیون و کلاسبندی آمده است.
جدول 1- مقایسه الگوریتم کلاسبندی و رگرسیون
مزایا و معایب رگرسیون
مزایا
شهود با ارزش: کمک میکند تا رابطه بین متغیرهای متمایز را تحلیل کرده و به فهم درستی از داده دست یابیم.
قدرت پیشبینی: پیشبینی مقادیر متغیر وابسته با دقت بالا با استفاده از متغیرهای مستقل
انعطافپذیری: الگوریتمهای رگرسیون، ابزارهایی انعطافپذیر برای یافتن یا پیشبینی کردن طیف وسیعی از مدلها هستند.
سهولت در تفسیر: به سادگی میتوان نتایج تحلیلی از رگرسیون را در قالب چارتها و نمودارهای گرافیکی ترسیم کرد.
معایب
فرضیات غلط: الگوریتم رگرسیون مبتنی بر فرضیات متعدد است که منتهی به فرضیات غلط در دنیای واقعی میشود. این فرضیات شامل نرمال بودن خطاها، خطی بودن و مستقل بودن متغیرها میشود.
تطبیق بیش از حد (Overfitting): مدلهای رگرسیون زمانیکه بیش از حد توسط داده آموزشی شخصیسازی شوند، ممکن است که عملکرد ناکافی در مواجهه با دادههای جدید و قبلا دیده نشده، داشته باشند.
داده پرت: مدلهای رگرسیون نسبت به موارد استثنایی حساس هستند و در نتیجه این مساله روی نتایج پیشبینی تحلیلی، اثر قابل توجهی میگذارد.
مزایا و معایب کلاسبندی
مزایا
دقت در پیشبینی: با آموزش مدل، الگوریتم کلاسبندی در عمل پیشبینی میتواند به دقت بالایی دست یابد.
انعطافپذیری: الگوریتمهای کلاسبندی، کاربردهای متعددی همچون فیلتر کردن ایمیلهای اسپم، تشخیص و شناسایی گفتار و تصویر دارند.
مجموعه داده قابل مقیاسدهی: به سادگی در کاربردهای زمان-واقعی که توانایی مقیاسدهی بالا به مجموعه دادههای عظیم را دارند، قابل استفاده است.
موثر و قابل تفسیر: الگوریتمهای کلاسبندی به طور موثری با مجموعه دادههای عظیم کار میکنند و میتوانند آنها را به سرعت کلاسبندی کنند، به طوریکه به سادگی نیز قابل تفسیر باشد. این روشها، فهم بهتری از رابطه بین متغیرها و مقدار هدف، فراهم میکنند.
معایب
گرایش (Bias): اگر داده آموزشی، نماینده داده کامل نباشد، برخی از دادههای آموزشی ممکن است که اگوریتم کلاسبندی را دچار گرایش نادرست کنند.
داده نامتوازن (Imbalanced): اگر کلاسها در مجموعه داده به طور مساوی متوازن نباشند، الگوریتم کلاسبندی به نفع کلاس غالب عمل کرده و کلاس مغلوب را نادیده میگیرد. برای مثال، در یک مجموعه داده با دو کلاس که به ترتیب 85 و 15 درصد، داده را تشکیل میدهند، الگوریتم کلاسبندی، کلاس غالب را با دقت 85 درصد نمایش میدهد و کلاس مغلوب را کلا نادیده میگیرد.
انتخاب شاخصها: اگر الگوریتمهای کلاسبندی، شاخصها را تعریف نکنند، پیشبینی مقدار هدف با چندین شاخص تعریف نشده، دشوار میشود.
کاربردهای رگرسیون
پیشبینی قیمت سهام: الگوریتمهای رگرسیون، یک رابطه ریاضی بین قیمت سهام و فاکتورهای مرتبط با آن برای پیشبینی دقیق با استفاده از دادههای قبلی، روندهای مشاهده شده و الگوهای موجود تولید میکنند.
پیشبینی میزان فروش: سازمانهایی که استراتژی فروش، میزان کالاهای انبار شده و کمپینهای بازاریابی طراحی میکنند، از دادههای فروش قبلی، روندها و الگوها برای پیشبینی میزان فروش در آینده استفاده میکنند. این کار به آنها کمک میکند تا میزان فروش عمده، خرده و آنلاین و همچنین سایر فروشها را بتوانند حدس بزنند.
ارزشگذاری املاک: معادلات ریاضی را برای پیشبینی مدلهایی که میزان ارزش املاک را کشف میکنند، پایهگذاری میکنند. یک سازمان میتواند به راحتی قیمت ملک را بر اساس امکانات، ابعاد و موقعیت آن به همراه دادههای قبلی شامل ارزش مبتنی بر بازار و الگوهای فروش، مشخص کند. این کار به طور فراگیر توسط افراد حرفهای در زمینه بازار ملک، فروشندهها و خریداران برای ارزیابی میزان هزینه و سرمایه لازم در بازار ملک، استفاده میشود.
کاربردهای کلاسبندی
فیلتر کردن ایمیلهای اسپم: برای آموزش کلاسبند، از داده برچسبگذاری شده جهت کلاسبندی ایمیلها استفاده میشود. فیلتر کردن ایمیلها با تحلیل دو نوع داده دستهای که متعلق به دو گروه اسپم و غیر اسپم هستند، انجام میشود. ایمیلهای فیلتر شده به طور خودکار به کلاس مرتبط و با توجه به بردار شاخص ورودی به کلاسبند، تخصیص مییابند.
امتیازدهی اعتبار: امتیاز اعتبار را میتوان به کمک یک الگوریتم کلاسبندی، مشخص کرد. در اینجا، تاریخچه مشتری، میزان تراکنشها، وامهای گرفته شده، درآمد، اطلاعات شخصی و سایر فاکتورها توسط الگوریتم تحلیل شده تا در مورد اینکه آیا وام جدید به مشتری میتواند تعلق بگیرد، تصمیمگیری انجام شود.
شناسایی تصویر: کلاسبند به کمک داده برچسبگذاری شده، آموزش میبیند تا برای پیشبینی تصاویر بر اساس کلاسهای موجود، آماده شود. الگوریتمهای کلاسبندی میتوانند به طور خودکار، تصاویر جدید را به کلاسهای مختلف دستهبندی کنند.
چه زمانی از رگرسیون استفاده شود و چه زمانی از کلاسبندی؟
استفاده از کلاسبندی و رگرسیون در زمینههای مختلف به فاکتورهای زیر بستگی دارد:
– نوع داده: نوع داده به عنوان داده ورودی در رگرسیون و کلاسبندی میتواند پیوسته یا دستهای باشد. اما مقدار هدف در رگرسیون، پیوسته است، در حالیکه در کلاسبندی، دستهای است.
– هدف: رگرسیون میخواهد مقادیر پیوسته دقیق همچون سن، دما، ارتفاع، قیمت، نرخ و غیره را پیشبینی کند. از طرفی، کلاسبندی، دسته متعلق به یک کلاس همچون اسپم بودن یا نبودن یک ایمیل را میخواهد مشخص کند.
– دقت مورد نیاز: رگرسیون، بیشتر بر روی دستیابی به بالاترین دقت لازم با کاهش خطای پیشبینی همچون خطای مطلق میانگین یا خطای مربع میانگین تمرکز دارد. از سوی دیگر، کلاسبندی، بر روی دستیابی به دقت بالای مرتبط با یک معیار خاص برای مساله مورد نظر همچون نمودار ROC (ویژگی عملکرد گیرنده – Receiver Operating Characteristics)، دقت (Precision) یا یادآوری (Recall) تمرکز دارد.
منبع: https://www.analyticsvidhya.com https://www.simplilearn.com