تمام آنچه که برای دانستن یادگیری ماشین نیاز دارید که شامل انواع آن، کاربردها، شغلهای مرتبط و نحوه شروع کار در این صنعت میشود، را در این مقاله خواهید یافت.
فهم فناوریهایی که نوآوری را باعث میشوند، دیگر یک فرآیند خاص و مرتبط با طبقه ثروتمندان نیست بلکه یک ضرورت است. در رأس جبهه این تغییرات و نوآوریها، توسعه و پیشرفتی تحت عنوان یادگیری ماشین قرار دارد. این مقاله، میخواهد یادگیری ماشین را توضیح دهد و این کار از طریق فراهم کردن یک راهنمای جامع برای مبتدیها و علاقمندان انجام میدهد. تعریف یادگیری ماشین، انواع آن، کاربردها و ابزارهای مورد استفاده در این زمینه، بررسی خواهند شد. همچنین به مسیرهای شغلی مختلف در یادگیری ماشین اشاره میشود و راهنمایی لازم برای نحوه شروع کار در این حوزه جذاب فراهم خواهد شد.
یادگیری ماشین چیست؟
یادگیری ماشین، که معمولا به طور خلاصه ML نامیده میشود، یک زیرمجموعه از هوش مصنوعی (Artificial Intelligenece یا AI ) است که بر توسعه الگوریتمهای رایانهای تمرکز دارد که به طور خودکار از طریق تجربه کردن به کمک دادهها، بهبود مییابد. به طور سادهتر میتوان گفت که یادگیری ماشین، قابلیت یادگیری از دادهها و تصمیمگیری یا پیشبینی بدون اینکه به طور اختصاصی برای این کار برنامهنویسی بشوند، را در رایانهها ایجاد میکند.
در هسته مرکزی یادگیری ماشین، ایجاد و پیادهسازی الگوریتمهایی که تصمیمگیری و پیشبینی را تسهیل میکنند، قرار دارد. این الگوریتمها طوری طراحی شدهاند که عملکرد خود را در طول زمان بهبود دهند و به مرور همچنان که دادههای بیشتری را پردازش میکنند، دقیقتر و موثرتر شوند.
در برنامهنویسی رایج و سنتی، یک رایانه، مجموعهای از دستورات از پیش تعریف شده را برای انجام یک کار دنبال میکند. از طرفی، در یادگیری ماشین، به رایانه یک مجموعه از مثالها (دادهها) و یک کار مشخص برای انجام دادن، ارائه میشود اما این وظیفه رایانه است که از نحوه انجام این کار بر اساس مثالهای داده شده به آن، سر در بیاورد و آن را پیدا کند.
برای نمونه، اگر از یک رایانه بخواهیم که در تصاویر، گربهها را تشخیص دهد، ما به رایانه دستورات مشخص در رابطه با اینکه شکل گربه چگونه است، نمیدهیم. به جای آن، ما هزاران تصویر از گربههای مختلف را به رایانه ارائه میکنیم و اجازه میدهیم تا الگوریتم یادگیری ماشین خودش الگوهای مشترک و شاخصهایی که یک گربه را تعریف میکنند، را بیابد. در طول زمان، همچنان که الگوریتم، تصاویر بیشتری را پردازش میکند، در تشخیص گربهها بهتر میشود و حتی این کار را در صورتیکه با تصاویر هرگز دیده نشده مواجه شود، انجام میدهد.
این توانایی برای یادگیری از داده و بهبود در طول زمان، یادگیری ماشین را به طور غیرقابل باوری قدرتمند و همهکاره میسازد. این مساله، نیروی پیشران بسیاری از پیشرفتهای وابسته به فناوری روز است که شامل دستیارهای صوتی و سیستمهای پیشنهاددهنده تا ماشینهای خودران و تحلیلهای پیشبینی کننده مختلف میشود.
یادگیری ماشین در مقابل هوش مصنوعی و یادگیری عمیق
اغلب، یادگیری ماشین با هوش مصنوعی یا یادگیری عمیق اشتباه گرفته میشود. بیایید نگاهی به تفاوتهای این مفاهیم با هم داشته باشیم. هوش مصنوعی یا AI به توسعه برنامههایی که هوشمندانه رفتار کرده و از طریق یک مجموعه از الگوریتمها، سعی در تقلید هوش انسان دارند، گفته میشود. این حوزه بر روی سه مهارت تمرکز دارد:یادگیری، استدلال و خودتصحیحی برای دستیابی به حداکثر راندمان و بهرهوری. AI میتواند به برنامههای مبتنی بر یادگیری ماشین و یا حتی برنامههای رایانهای اختصاصی نیز اشاره داشته باشد.
یادگیری ماشین یا ML یک زیرمجموعه از AI است که از الگوریتمهایی استفاده میکند که از داده برای پیشبینی یاد میگیرند. این پیشبنیها میتواند از طریق یادگیری با ناظر (supervised learning) که الگوریتمها در آن الگوها را از داده موجود یاد میگیرند، یا یادگیری بدون ناظر (unsupervised learning) که الگوهای کلی موجود در داده کشف میشوند، تولید شوند. مدلهای ML میتوانند مقادیر عددی را بر اساس دادههای ثبت شده پیشبینی کنند، رخدادها را به دستههای درست و نادرست دستهبندی کنند و نقاط داده را بر اساس اشتراک بین آنها، خوشهبندی کنند.
یادگیری عمیق، از سوی دیگر، یک زیرشاخه از یادگیری ماشین است که الگوریتمهای آن مبتنی بر ساختار شبکه عصبی مصنوعی (artificial neural networks) یا ANN چند لایه است که الهام گرفته شده از ساختار مغز انسان است.
برخلاف الگوریتمهای معمول و رایج یادگیری ماشین، الگوریتمهای یادگیری عمیق کمتر خطی هستند و پیچیدگی بیشتری دارند. همچنین به صورت سلسله مراتبی بوده و توانایی یادگیری از مقادیر عظیم داده را دارند و میتوانند نتایج با دقت خیلی بالا تولید کنند. ترجمه به زبان دیگر، تشخیص تصویر و پزشکی شخصیسازی شده، مثالهایی از کاربردهای یادگیری عمیق است.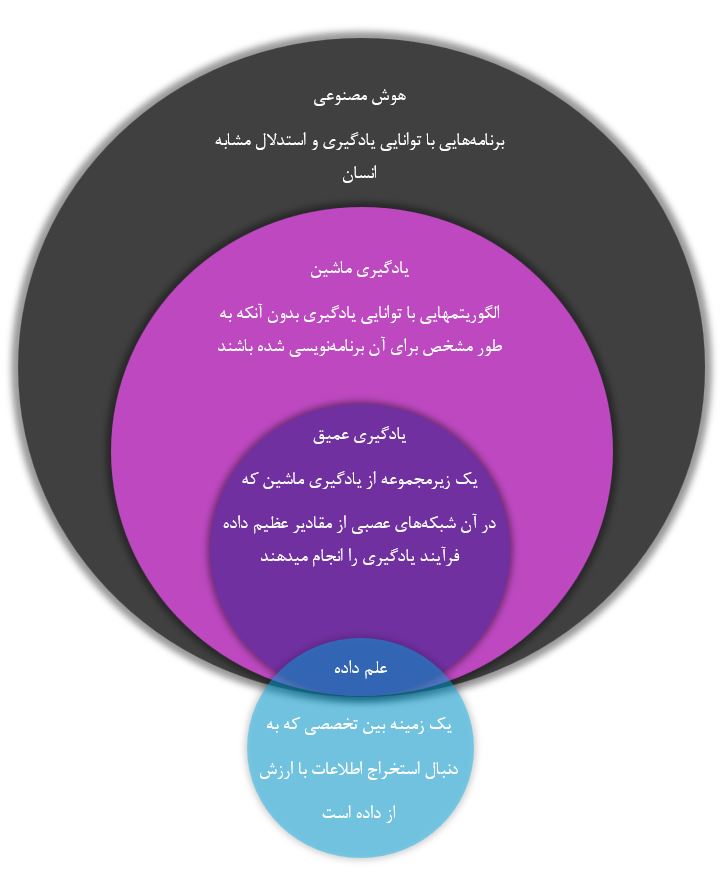
شکل ۱- مقایسه حوزههای مختلف مرتبط با تحلیل داده
اهمیت یادگیری ماشین
در قرن ۲۱ام، داده و اطلاعات، نفت خام جدید است و یادگیری ماشین موتوری است که این دنیای داده-محور را قدرتمند میسازد. در عصر دیجیتال حاضر، یک فناوری حیاتی و مهم است که اهمیت آن بیش از این قابل تاکید نیست. این مساله خود را در رشد صنعت بدین شکل نشان میدهد که اداره آمار شغلی پیشبینی رشد ۲۶ درصدی برای شغلها در فاصله سالهای ۲۰۲۳ تا ۲۰۳۳ را کرده است.
در اینجا برخی از دلایل اهمیت یادگیری ماشین در دنیای مدرن رو مرور میکنیم:
- پردازش داده: یکی از دلایل اصلی اهمیت یادگیری ماشین، توانایی آن در تعامل و درک بهتر حجمهای عظیم داده است. با توجه به انفجار اطلاعات حاصل از شبکههای اجتماعی، حسگرها و سایر منابع، روشهای تحلیل داده قدیمی و سنتی دیگر کفایت نمیکنند. الگوریتمهای یادگیری ماشین میتوانند این مقادیر عظیم داده را پردازش کرده و الگوهای پنهان موجود در آنها را آشکار کنند و دید خوبی برای تصمیمگیرهای آتی در مورد آنها به ما بدهند.
- ایجاد انگیزه نوآوری:یادگیری ماشین باعث ایجاد نوآوری و راندمان بهتر در بخشهای مختلف میشود. در ادامه برخی از این موارد آمده است:
- بهداشت و درمان: برای پیشبینی شیوع بیماریها، طرحهای شخصی برای درمان بیماران و بهبود دقت تصویربرداری پزشکی، از الگوریتمها استفاده میشود.
- مالی: یادگیری ماشین برای امتیازدهی اعتباری، معاملات الگوریتمی و تشخیص تقلب استفاده میشود.
- خردهفروشی: سیستمهای پیشنهاد دهنده، زنجیره تامین کالا و سرویس مشتریان همگی میتوانند از مزایای یادگیری ماشین بهرهمند شوند.
- روشهای استفاده شده همچنین میتوانند کاربردهایی در سایر بخشها از کشاورزی گرفته تا آموزش و سرگرمی داشته باشند.
- ایجاد توانمندی در خودکار کردن سیستمها: یادگیری ماشین یک ابزار توانمندسازی کلیدی برای اتوماسیون و خوکارکردن سیستمها است. از طریق یادگیری از داده و بهبود در طول زمان، الگوریتمهای یادگیری ماشین میتوانند کارهای دستی قبلی را انجام داده و انسان را به منظور تمرکز بیشتر روی فعالیتهای خلاقانه و پیچیدهتر، رها سازند. این نه تنها باعث افزایش راندمان میشود بلکه قابلیتهای جدیدی را برای نوآوری فراهم میکند.
یادگیری ماشین چگونه کار میکند؟
درک نحوه عملکرد یادگیری ماشین، شامل بررسی یک فرآیند گام به گام میشود که داده خام را به مفاهیم شهودی با ارزش تبدیل میکند. بیایید این فرآیند را به بخشهای کوچکتر تقسیم کنیم:
گام ۱- جمعآوری داده
گام اول در فرآیند یادگیری ماشین، جمعآوری داده است. داده به نوعی مایه حیات شریانی یادگیری ماشین است و کیفیت و کمیّت داده شما میتواند به طور مستقیم بر روی عملکرد مدل شما اثرگذار باشد. داده میتواند از منابع مختلف همچون مجموعه دادهها (databases)، فایلهای متنی (text files)، تصاویر (images)، فایلهای صوتی (audio files) و حتی ناشی از صفحات وب جمعآوری شود.
وقتی داده جمعآوری شد، این داده نیاز به آمادهسازی برای یادگیری ماشین دارد. این فرآیند شامل سازماندهی داده به فرمت مناسب همچون فایل CSV یا یک دیتابیس و اطمینان از اینکه داده به مساله مورد نظر که به دنبال حل آن هستیم، مرتبط باشد، میشود.
گام ۲- پیشپردازش داده
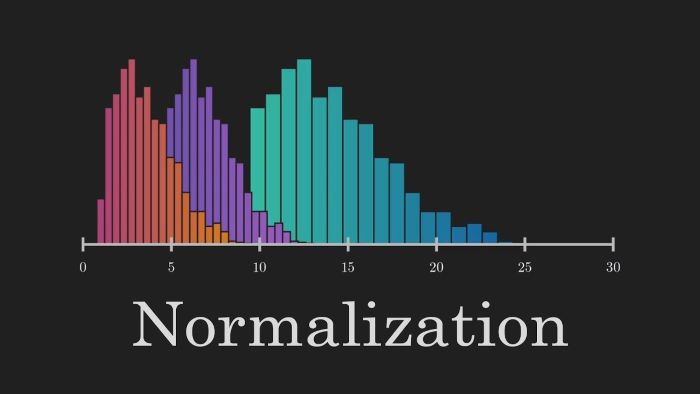
پیشپردازش داده یک گام حیاتی در فرآیند یادگیری ماشین است. این مرحله شامل پاکسازی داده (حذف دادههای تکراری، تصحیح خطاها)، تعیین تکلیف دادههای از دست رفته (با حذف آنها یا پر کردن آنها) و نرمالسازی داده (تغییر مقیاس داده به یک فرمت استاندارد) میشود.
پیشپردازش، کیفیت داده شما را بهبود میبخشد و اطمینان میدهد که مدل یادگیری ماشین شما میتواند آن را درست تفسیر کند. این گام میتواند به طور قابل توجهی دقت مدل شما را افزایش دهد.
گام ۳- انتخاب مدل درست و مناسب
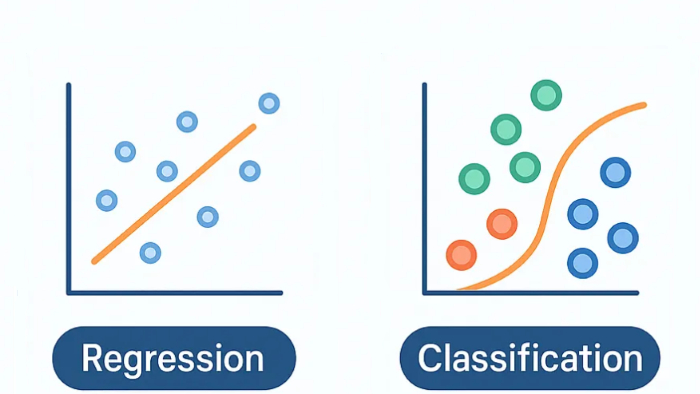
پس از آمادهسازی داده، گام بعدی انتخاب مدل یادگیری ماشین است. انواع زیادی از مدلها برای انتخاب از بین آنها، وجود دارند که شامل رگرسیون خطی (Linear Regression)، درختهای تصمیمگیری (Decision Trees) و شبکههای عصبی (Neural Networks) میشوند. انتخاب مدل به ماهیت و طبیعت داده شما و مسالهای که سعی در حل آن دارید، خیلی بستگی دارد.
فاکتورهایی که در انتخاب یک مدل باید در نظر بگیرید شامل اندازه و نوع داده شما، پیچیدگی مساله و منابع محاسباتی در دسترس میشوند.
گام ۴- آموزش مدل
بعد از انتخاب مدل، گام بعدی آموزش آن توسط داده آمادهسازی شده است. آموزش شامل تغذیه مدل توسط داده و ایجاد فضا برای مدل جهت تنظیم پارامترهای داخلی آن برای پیشبینی بهتر خروجی میشود. در طول آموزش مدل، پرهیز از بیشبرازش (overfitting) – یا همان تطبیق بیش از حد – (که در آن مدل بر روی داده آموزشی خوب عمل میکند ولی بر روی داده جدید، ضعیف پیشبینی میکند) و کمبرازش (underfitting) – یا همان تطبیق کمتر از حد – (که مدل بر روی هر دو داده آموزش و جدید، ضعیف عمل میکند) اهمیت زیادی دارد.
گام ۵- ارزیابی مدل
پس از اینکه مدل آموزش داده شد، ارزیابی عملکرد آن بر روی دادههایی که مدل قبلا ندیده است، بسیار ضرروی است و باید قبل از به کار گرفته شدن آن در کاربرد واقعی انجام شود. از طریق فرآیندی تحت عنوان MLOps که راهکاری برای تلفیق توسعه نرمافزاری مبتنی بر یادگیری ماشین و به کارگیری سیستمهای یادگیری ماشین در کاربردهای واقعی است، تحلیل و مانیتورینگ سیستم یادگیری ماشین در این گام ابتدایی (ارزیابی مدل) متوقف نمیشود. این کار شامل ارزیابی مداوم برای تشخیص هر گونه انحراف مدل از مسیر خود (زمانیکه عملکرد مدل به دلیل تغییرات در الگوهای داده، تنزل مییابد) و حفظ کیفیت مدل در طول زمان میشود. مانیتورینگ پیوسته و راهکارهای آموزش مجدد سیستم، به سازمانها کمک میکنند تا از اثرگذاری و قابلیت اطمینان مدلهای خود در محیطهای تولید و توسعه، مطمئن باشند.
معیارهای رایج برای ارزیابی یک عملکرد مدل شامل دقت (accuracy) برای مسائل کلاسبندی، صحت (precision) و فراخوانی (recall) برای مسائل کلاسبندی باینری و خطای مربع میانگین (mean square error-MSE) برای مسائل رگرسیون میشود.
گام ۶- تنظیم پارامترها و بهینهسازی
فراتر از تنظیم مدل برای دقت بهتر، راهکار بهینهسازی ابرپارامترهای مدل توسط فرآیند MLOps، شامل ابزارهایی برای جستجوی خودکار ابرپارامترها، اطمینان از اثرگذاری و قابلیت بازتولیدی میشود. بسیاری از تیمها، زیرساختهای MLOps که از راهکار تنظیم ابرپارامترها پشتیبانی میکنند، را به کار میگیرند تا بتوانند آزمایشهای قابل تکرار و به خوبی مستند شده را در اختیار داشته باشند که در نهایت به آنها امکان بهینهسازی موثر و مفید را در طول زمان میدهد.
تکنیکهای تنظیم ابرپارامترها شامل جستجوی شبکه توری مانند (grid search) که در آن ترکیبهای مختلف پارامترها تست میشوند و اعتبارسنجی متقابل (cross validation) که در آن داده به زیرمجموعههای مستقل تقسیم شده و مدل توسط هر زیرمجموعه آموزش داده میشود تا این اطمینان حاصل شود که روی دادههای مختلف، خوب عمل میکند.
گام ۷- پیشبینیها و توسعه مدل به محیط کاری
توسعه و ارائه مدل به یک سیستم کاربردی شامل تلفیق آن با یک محیط تولیدی میشود که در آن مدل میتواند پیشبینیها یا ارائه شهود درباره دادهها را در لحظه انجام دهد. فرآیند MLOps به عنوان یک راهکار استاندارد برای خلاصهسازی این فرآیند بوجود آمده است. این راهکار شامل کنترل نسخه نرمافزار، مانیتورینگ و تست خودکار برای اطمینان از بازتولیدی و قابل اعتماد بودن مدل و همچنین مقاوم بودن آن به تغییرات احتمالی در محیط کار، میشود.
انواع یادگیری ماشین
به طور کلی میتوان یادگیری ماشین را به سه نوع مختلف بر حسب ماهیت سیستم یادگیرنده آن و داده در دسترس، دستهبندی کرد: یادگیری با ناظر (supervised)، یادگیری بدون ناظر (unsupervised) و یادگیری تقویتی (reinforcement). اجازه دهید تا هر کدام را جداگانه بررسی کنیم.
یادگیری با ناظر
یادگیری با ناظر، رایجترین نوع یادگیری ماشین است. در این رویکرد، مدل بر روی مجموعه داده برچسب گذاری شده (labeled) تحت آموزش قرار میگیرد. به عبارت دیگر، هر داده با یک برچسب که مدل سعی در پیشبینی آن دارد، همراه میشود. این برچسب میتواند هر چیزی از یک برچسب گروه یا یک مقدار عددی حقیقی باشد.
مدل، نگاشت بین ورودی (شاخصها) و خروجی (برچسب) را در طول فرآیند آموزش، فرا میگیرد. بعد از آموزش دیدن، مدل میتواند خروجی را برای داده ورودی جدید و قبلاً دیده نشده، پیشبینی کند.
مثالهای رایج از الگوریتمهای یادگیری با ناظر شامل رگرسیون خطی برای مسائل رگرسیون و رگرسیون لاجیستیک (logistic)، درختهای تصمیمگیری (decision trees) و ماشینهای بردار پشتیبان (support vector machines – SVM) برای مسائل کلاسبندی میشود. به زبان کاربردی، این فرآیند میتواند مشابه یک فرآیند تشخیص عکس باشد که در آن یک مجموعه داده از تصاویر که هر نمونه از آن برچسب مشخصی همچون “سگ” یا “گربه” را دارد، وجود دارد و یک مدل با ناظر میتواند تصاویر جدید را تشخیص داده و با دقت بالا دستهبندی کند.
یادگیری بدون ناظر
از سوی دیگر، یادگیری بدون ناظر را داریم که شامل آموزش مدل بر روی یک مجموعه داده بدون برچسب میشود. مدل، خود باید الگوها و روابط درون داده را به تنهایی پیدا کند. این نوع از یادگیری، اغلب برای خوشهبندی (clustering) و کاهش ابعاد (dimensionality reduction) استفاده میشود. خوشهبندی، گروهبندی نقاط داده مشابه با هم است در حالیکه کاهش ابعاد، کاهش تعداد متغیرهای تصادفی مورد نظر از طریق بدست آوردن یک مجموعه از متغیرهای اساسی است.
مثالهای معمول از الگوریتهای یادگیری بدون ناظر، شامل روش k-means برای مسائل خوشهبندی و تحلیل اجزاء اصلی (principal component analysis-PCA) برای مسائل کاهش ابعاد میشود. در اینجا نیز به زبان کاربردی، در حوزه کاری بازاریابی، یادگیری بدون ناظر اغلب برای دستهبندی پایگاه مشتریان یک شرکت یا کمپانی استفاده میشود. با مطالعه دقیق الگوهای خرید مشتریان، دادههای آماری افراد و سایر اطلاعات مرتبط، الگوریتم میتواند مشتریان را به بخشهای مجزایی تقسیم کند که رفتارها و خصوصیات مشابهی از خود نشان میدهند بدون اینکه برچسب مشخصی از قبل برای آنها وجود داشته باشد.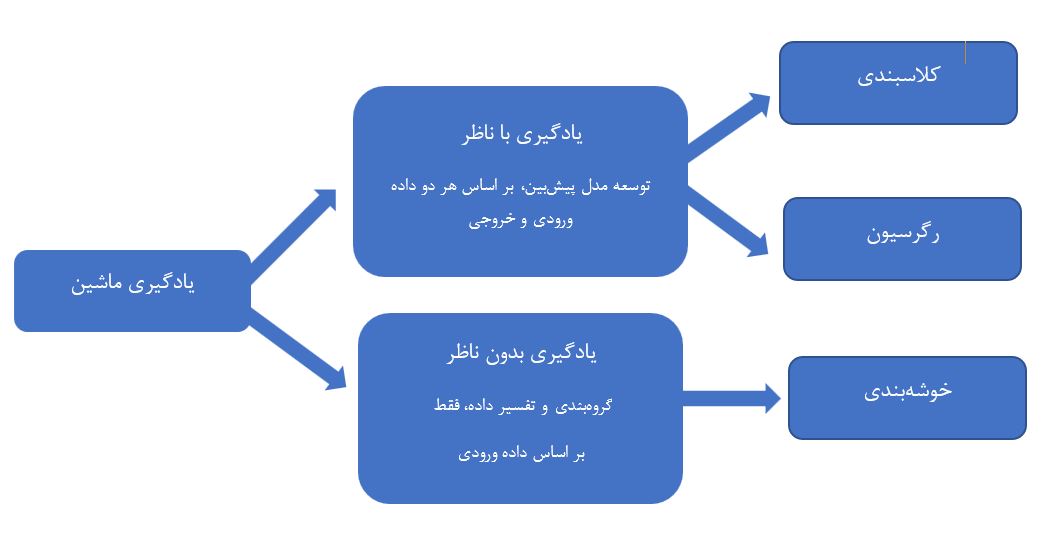
شکل ۲- مقایسه روشهای یادگیری با ناظر و بدون ناظر
یادگیری تقویتی
یادگیری تقویتی، نوعی از یادگیری ماشین است که یک عامل کارگزار (agent) یاد میگیرد تا از طریق تعامل با محیط خود، تصمیمگیری کند. این مامور برای کارهایی که انجام میدهد، جایزه میگیرد یا جریمه میشود (از طریق نقاط امتیازی) و هدف آن، حداکثر کردن جایزه نهایی است.
برخلاف یادگیری با ناظر و بدون ناظر، یادگیری تقویتی به طور ويژه برای مسائلی مناسب است که داده در آن سلسلهوار است و تصمیم گرفته شده در هر گام میتواند روی نتایج نهایی تاثیر بگذارد.
مثالهای پیچیده از یادگیری تقویتی شامل بازی کردن، رباتها، مدیریت منابع و بسیار موارد دیگر میشود.
درک میزان اثرگذاری یادگیری ماشین
در سال ۲۰۲۴، یادگیری ماشین یک عامل پیشبرد کلیدی در حوزههای گستردهای همچون بهداشت و درمان، مالی و علوم هواشناسی است. با ظهور هوش مصنوعی مولّد (generative AI)، تیمهای بازاریابی میتوانند محتوای شخصیسازی شده را در مقیاس بالا تولید کنند و در عین حال تامین کنندههای خدمات بهداشت و درمان، از یادگیری ماشین برای تشخیص اولیه بیماریها و راهکارهای درمانی متناسب با شخص بیمار، استفاده کنند. در میان این پیشرفتها، سازمانهای قانونگذار به طور روزافزون بر روی استانداردهای اخلاقی و حریم خصوصی دادهها متمرکز شدهاند تا از تحول رو به جلوی یادگیری ماشین با رویکرد مسئولیتپذیری در قبال این موارد، اطمینان حاصل کنند.
بهداشت و درمان
یادگیری ماشین از طریق بهبود دقت تشخیص بیماری و طرحهای درمان شخصیسازی شده، در حال ایجاد تحول عظیم در بهداشت و درمان است. برای نمونه، Med-PaLM 2 ارائه شده توسط گوگل، یک مدل زبانی عظیم تنظیم شده برای کاربردهای پزشکی و درمانی است که به پزشکان در تفسیر اطلاعات پزشکی پیچیده کمک میکند و در نهایت، فرآیند مراقبت از بیمار را بهبود میدهد.
مالی
در بخش مالی، یادگیری ماشین در تشخیص تقلب و مدیریت ریسک، نقش کلیدی دارد. بانکهای مهمی همچون JPMorgan، ابزارهای چت (chatbot) مبتنی بر هوش مصنوعی به منظور کمک به کارمندان بخش مدیریت دارایی و ثروت، توسعه دادهاند که فعالیتها را سادهتر کرده و تعامل با مشتریان را بهبود میدهد.
حمل و نقل
یادگیری ماشین در بطن تحول ایجاد شده توسط خودروهای خودران (self-driving) قرار دارد. کمپانیهایی همچون Tesla و Waymo از الگوریتمهای یادگیری ماشین برای تفسیر داده حسگرها به صورت زمان-واقعی استفاده میکنند تا به وسایل نقلیه امکان تشخیص و شناسایی اشیاء، تصمیمگیری و راهبری جادهای به صورت خودکار بدهد. به طور مشابه، سازمان حمل و نقل کشور سوئد نیز اخیرا با متخصصین بینایی ماشین و یادگیری ماشین برای بهینهسازی مدیریت زیرساختهای جادههای کشور، شروع به همکاری کرده است.
برخی کاربردهای یادگیری ماشین
کاربردهای یادگیری ماشین، همه جا در اطراف ما حضور دارند و اغلب پشت پرده برای بهبود زندگی روزمره مشغول به کار هستند. در اینجا برخی مثالهای واقعی آنها را بررسی میکنیم:
سیستمهای پیشنهاد دهنده (Recommendation systems)
سیستمهای پیشنهاد دهنده، یکی از کاربردهای واضح یادگیری ماشین است. کمپانیهایی همچون Netflix و Amazon از یادگیری ماشین برای تحلیل رفتارهای پسین مشتری و پیشنهاد محصولات یا فیلمهای مورد علاقه به شما، استفاده میکنند.
دستیارهای صوتی (Voice assistants)
دستیارهای صوتی همچون Siri، Alexa و دستیار گوگل، از یادگیری ماشین برای فهم و درک دستورهای صوتی شما و ارائه پاسخهای مرتبط، استفاده میکنند. آنها به طور دائم از تعاملات و رفتار شما برای بهبود عملکرد خودشان، میآموزند.
تشخیص تقلب (Fraud detection)
بانکها و موسسات کارت اعتباری از یادگیری ماشین برای تشخیص تراکنشهای مالی مشکوک و تقلبآمیز استفاده میکنند. با تحلیل الگوهای رفتاری عادی و غیرعادی، آنها میتوانند فعالیت مشکوک را در لحظه هشدار دهند.
رسانه اجتماعی (Social media)
پلتفرمهای رسانه اجتماعی از یادگیری ماشین برای مقاصد مختلف از شخصیسازی فیدها (feeds) تا فیلتر کردن محتوای نامناسب، استفاده میکنند.
ابزارهای یادگیری ماشین
در دنیای یادگیری ماشین، دسترسی به ابزار مناسب به اندازه درک مفاهیم آن، اهمیت دارد. این ابزارها که شامل زبانهای برنامهنویسی و کتابخانههای آنها میشود، بلوکهای سازنده برای پیادهسازی و توسعه الگوریتمهای یادگیری ماشین را فراهم میکنند. بیایید برخی از ابزارهای بیشتر شناخته شده در یادگیری ماشین را بررسی کنیم:
زبان پایتون برای یادگیری ماشین
پایتون یک زبان برنامهنویسی مشهور برای یادگیری ماشین است که به دلیل سادگی و خوانایی بالایی که دارد، به یک ابزار توانمند برای تازهکاران تبدیل شده است. همچنین این زبان دارای اکوسیستم قوی از کتابخانهها است که به طور خاص برای یادگیری ماشین طراحی شدهاند.
کتابخانههایی همچون Numpy و Pandas برای کار با داده و تحلیل آن استفاده میشوند در حالیکه Matplotlib برای مصورسازی داده به کار میرود. کتابخانه Scikit-learn گستره وسیعی از الگوریتمهای یادگیری ماشین را فراهم میکند و Tensorflow و PyTorch نیز برای ساختن و آموزش شبکههای عصبی استفاده میشوند. PyTorch به طور ویژه در میان محققین بسیار شناخته شده است و نسخه جدید آن PyTorch 2.0 شاخصهای جدیدی برای افزایش سرعت و راحتی کار فراهم کرده است.
پایتون به عنوان زبان غالب و مسلط در حوزه یادگیری ماشین باقی مانده است اما خالی از لطف نیست کاربردی بودن آن در سایر حوزههای نیز بررسی شود:
- Hugging face transformers برای پردازش زبان طبیعی (Natural Language Processing – NLP) و هوش مصنوعی مولد (Generative AI)
- LangChain برای ساختن ابزارهای کاربردی مبتنی بر مدلهای زبانی
زبان برنامهنویسی R برای یادگیری ماشین
R، زبان پرکاربرد دیگری در حوزه یادگیری ماشین است، به خصوص برای تحلیل آماری. این ابزار دارای یک اکوسیستم غنی از بستهها (packages) است که استفاده از آن برای پیادهسازی الگوریتمهای یادگیری ماشین را ساده میسازد.
بستههایی همچون caret، mlr و randomForest، الگوریتمهای یادگیری ماشین مختلفی را از رگرسیون و کلاسبندی تا خوشهبندی و کاهش ابعاد، فراهم میکند.
TensorFlow
TensorFlow یک کتابخانه منبع-باز قدرتمند برای محاسبات عددی است که به طور خاص برای یادگیری ماشین در مقیاس بالا مناسب است. این ابزار توسط تیم Google Brain توسعه یافته و از هر دو سختافزار CPU و GPU پشتیبانی میکند.
TensorFlow به شما اجازه میدهد که شبکههای عصبی پیچیده را ساخته و تحت آموزش قرار دهید که آن را به انتخاب خوبی برای کاربردهای یادگیری عمیق تبدیل میکند.
Scikit-learn
Scikit-learn یک کتابخانه پایتون است که گستره وسیعی از الگوریتمهای یادگیری ماشین برای هر دو بخش یادگیری با ناظر و بدون ناظر فراهم میکند. این ابزار با واسط کاربری ساده و روشن خود و همچنین مستندسازی قوی آن شناخته میشود.
Scikit-learn اغلب برای دادهکاوی و تحلیل داده استفاده میشود و به خوبی با سایر کتابخانههای پایتون همچون Numpy و Pandas، تجمیع میشود.
Keras
Keras یک واسط کاربری سطح بالای شبکههای عصبی است که به زبان پایتون نوشته شده و توانایی اجرا بر روی کتابخانههای TensorFlow و CNTK یا Theano را نیز دارد. این ابزار با تمرکز بر ایجاد فضای آزمایش سریع و تست سریع، توسعه یافته است.
Keras یک واسط کاربری کاربرپسند برای ساختن و آموزش شبکههای عصبی ایجاد میکند که آن را به یک انتخاب عالی برای تازهکاران در حوزه یادگیری عمیق تبدیل کرده است.
PyTorch
PyTorch یک کتابخانه منبع-باز یادگیری ماشین است که بر پایه کتابخانه Torch بنا نهاده شده است. این ابزار توسط انعطافپذیری و راندمان بالایی که دارد شناخته میشود و آن را در میان محققان، بسیار مشهور ساخته است.
PyTorch، کاربردهای متعددی را پشتیبانی میکند، از بینایی ماشین تا پردازش زبان طبیعی. یکی از ویژگیهای کلیدی آن، گراف محاسباتی پویا است که محاسبات منعطف و بهینهشده را میسر میسازد.
شغلهای برتر در حوزه یادگیری ماشین
یادگیری ماشین طیف گستردهای از فرصتهای شغلی بوجود آورده است. از علوم داده تا مهندسی هوش مصنوعی، نیاز به متخصصین و افراد حرفهای با مهارتهای یادگیری ماشین، بسیار بالا رفته است. بیایید برخی از این مسیرهای شغلی را بررسی کنیم:
دانشمند داده (Data scientist)
یک دانشمند داده، از روشهای علمی، فرآیندها، الگوریتمها و سیستمها برای استخراج دانش و شهود از دادههای ساختار یافته و غیرساختار یافته استفاده میکند. یادگیری ماشین، یک ابزار کلیدی در مجموعه مهارتهای یک دانشمند داده است که به آن اجازه میدهد تا پیشبینیهای لازم را انجام داده و الگوها را در داده آشکار سازد.
مهارتهای کلیدی:
- تحلیل آماری
- برنامهنویسی (پایتون و R)
- یادگیری ماشین
- مصورسازی داده
- حل مساله
ابزار ضروری:
- پایتون
- R
- SQL
- Hadoop
- Spark
- Tableau
مهندس یادگیری ماشین
یک مهندس یادگیری ماشین، سیستمهای یادگیری ماشین را طراحی و پیادهسازی میکند. آنها، آزمایشهای یادگیری ماشین را با استفاده از زبانهای برنامهنویسی همچون پایتون و R، راهاندازی کرده و الگوریتمها و کتابخانههای یادگیری ماشین را به کار میگیرند.
مهارتهای کلیدی:
- برنامهنویسی (پایتون، R و جاوا)
- الگوریتمهای یادگیری ماشین
- آمار
- طراحی سیستم
ابزارهای ضروری:
- پایتون
- Tensorflow
- Scikit-learn
- PyTorch
- Keras
- MLflow, Kubeflow, Docker و Kubernetes برای توسعه مدل
دانشمند محقق
یک دانشمند محقق در حوزه یادگیری ماشین، تحقیقات لازم برای پیشرفت در یادگیری ماشین را هدایت میکند. آنها در هر دو بخش آکادمیک و صنعتی فعالیت میکنند و الگوریتمها و روشهای نوین را توسعه میدهند.
مهارتهای کلیدی:
- فهم عمیق الگوریتمهای یادگیری ماشین
- برنامهنوسی (پایتون و R)
- روش تحقیق
- مهارتهای ریاضی قوی
ابزارهای ضروری:
- پایتون
- R
- TensorFlow
- PyTorch
- MATLAB
- Hugging Face Model Hub
منبع: https://www.datacamp.com