این مبحث تئوری، اکثر سوالات رایج در رابطه با یادگیری عمیق را پاسخ میدهد و جنبههای مختلف یادگیری عمیق را با مثالهای موجود در دنیای واقعی، مورد کاوش و تحلیل قرار میدهد.
یادگیری عمیق چیست؟
یادگیری عمیق (Deep Learning)، یک از انواع یادگیری ماشین (Machine Learning) است که به رایانهها، فعالیتهای مشخصی را از طریق مثال آموزش میدهد، درست شبیه به آنچه که انسانها انجام میدهند. آموزش به یک رایانه برای تشخیص گربه را در نظر بگیرید: به جای اینکه با آن بگوییم به دنبال سبیلها، گوشها و دم گربه باشد، به آن هزاران تصویر از گربههای مختلف را نشان میدهیم. رایانه، الگوهای مشترک را خودش پیدا میکند و یاد میگیرد که چگونه یک گربه را شناسایی کند. این نکته، چکیده و خلاصله یادگیری عمیق است.
به زبان فنی و تکنیکی، یادگیری عمیق از چیزی تحت عنوان شبکه عصبی (Neural Network) استفاده میکند که از مغز انسان الهام گرفته شده است. این نوع شبکه متشکل از لایههایی از گرههای (Nodes) مرتبط با هم است که اطلاعات را پردازش میکنند. هر چه تعداد لایهها بیشتر باشد، شبکه عمیقتر میشود و امکان یادگیری شاخصهای پیچیدهتر و انجام کارهای دشوارتر را مییابد.
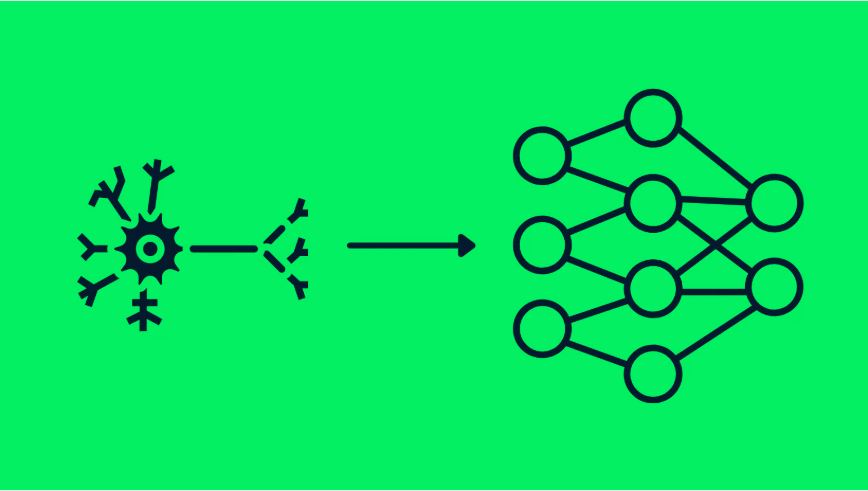
شکل ۱- تشابه بین نرونهای مغزی و شبکههای عصبی
سیر تکامل یادگیری ماشین تا یادگیری عمیق
یادگیری ماشین چیست؟
یادگیری ماشین، خود یک زیرمجموعه از هوش مصنوعی (AI) است که رایانهها را برای یادگیری از داده و انجام تصمیمگیری بدون نیاز به برنامهنویسی اختصاصی برای مساله خاص، توانمند میسازد. این شاخه از هوش مصنوعی، روشهای مختلف و الگوریتمهای متنوعی را در بر میگیرد که به سیستمها، امکان تشخیص الگوها، پیشبینی کردن و بهبود عملکرد در طول زمان را میدهد.
چگونه یادگیری عمیق از یادگیری ماشین متمایز میشود؟
در حالیکه یادگیری ماشین، به خودی خود یک فناوری متحول کننده به شمار میرفته است، یادگیری عمیق این پدیده را از طریق خودکار کردن و اتوماسیون بسیاری از کارها که معمولا برای انجام آنها نیاز به تخصص انسانی است، یک گام فراتر برده است.
یادگیری عمیق، ضرورتاً یک زیرمجموعه تخصصی از یادگیری ماشین است که از طریق شبکههای عصبی با سه لایه یا بیشتر که در آن به کار رفته است، متمایز میشود. این شبکههای عصبی، تلاش میکنند که رفتار مغز انسان را شبیهسازی کنند – اگر چه خیلی از توانایی آن فاصله دارند – تا بتوانند از مقادیر عظیم داده چیزی یاد بگیرند.
اهمیت مهندسی شاخص
مهندسی شاخص (feature engineering)، فرآیند انتخاب، تبدیل یا ایجاد متغیرهای مرتبط که تحت عنوان شاخص شناخته میشوند، از داده خام برای استفاده در مدلهای یادگیری ماشین است.
برای مثال، اگر شما میخواهید یک مدل پیشبینی هوا بسازید، داده خام احتمالا شامل دما، رطوبت، سرعت باد و فشار هوا میشود. مهندسی شاخص در اینجا عبارت است از تعیین اینکه کدامیک از این شاخصها برای پیشبینی هوا، مهمتر است و همچنین تبدیل آنها ( به عبارت دیگر تبدیل دما از مثلا معیار فارنهایت به سلسیوس) برای بهبود کارکرد آنها در مدل.
در یادگیری ماشین، مهندسی شاخص اغلب یک فرآیند دستی و زمانبر است که به تخصص در یک زمینه خاص نیاز دارد. هر چند که، یکی از مزایای یادگیری عمیق آن است که میتواند به صورت خودکار شاخصهای مرتبط را از داده خام یاد بگیرد و دخالت به صورت دستی در این فرآیند را حذف کند.
چرا یادگیری عمیق مهم است؟
دلایل اینکه یادگیری عمیق به شکل یک استاندارد صنعتی در آمده است، عبارت است از:
– کار با داده غیر ساختار یافته: مدلهای آموزش دیده روی داده ساختار یافته میتوانند به سادگی از داده غیر ساختار یافته، یاد بگیرند که این موضوع باعث میشود تا زمان و منابع در طی استانداردسازی مجموعه دادهها کاهش یابند.
– کار با دادههای عظیم: به دلیل ظهور واحدهای پردازش گرافیکی (GPUs)، مدلهای یادگیری عمیق میتوانند مقادیر عظیم داده را با سرعت خیلی بالا پردازش کنند.
– دقت بالا: مدلهای یادگیری عمیق، بالاترین دقت در نتایج را در حوزههای مختلفی همچون بینایی ماشین، پردازش زبان طبیعی (NLP) و پردازش صوت فراهم میکنند.
– تشخیص الگو: اکثر مدلها نیاز به دخالت مهندس یادگیری ماشین دارند اما مدلهای یادگیری عمیق میتوانند تمامی انواع الگوها را به صورت خودکار ردیابی کنند.
در این مبحث تئوری، میخواهیم به دنیای یادگیری عمیق جهش کرده و تمامی مفاهیم کلیدی مورد نیاز برای شروع کار در حوزه هوش مصنوعی را کشف کنیم.
مفاهیم اصلی یادگیری عمیق
قبل از جهش به درون پیچیدگیهای الگوریتمهای یادگیری عمیق و کاربردهای آنها، ضروری است که مفاهیم پایهای که این فناوری را تا این حد مهم و انقلابی کرده است، درک کنیم. این بخش، شما را با اجزاء سازنده یادگیری عمیق که شامل شبکههای عصبی، شبکههای عصبی عمیق و توابع فعالسازی میشود، آشنا میکند.
شبکههای عصبی
در بطن یادگیری عمیق، شبکههای عصبی قرار دارند که مدلهای محاسباتی الهام گرفته از مغز انسان هستند. این شبکهها شامل گرهها یا نرونهای به هم متصل هستند که به کمک یکدیگر، اطلاعات را پردازش کرده و در مورد آنها تصمیمگیری میکنند. درست مشابه مغز انسان که نواحی مختلفی برای کارهای مختلف دارد، یک شبکه عصبی نیز لایههای اختصاصی برای توابع خاص دارد.
شبکههای عصبی عمیق
چیزی که یک شبکه عصبی را عمیق میسازد، تعداد لایههای آن بین ورودی و خروجی است. یک شبکه عصبی عمیق دارای لایههای متعدد است که به آن اجازه میدهد تا شاخصهای پیچیدهتر را یاد گرفته و پیشبینیهای دقیقتری داشته باشد. عمق این شبکهها است که نام یادگیری عمیق و قدرت آنها در حل مسائل پیچیده را یادآوری میکند.
توابع فعالسازی
در یک شبکه عصبی، توابع فعالسازی مشابه تصمیمگیرندگان عمل میکنند. آنها تعیین میکنند که چه اطلاعاتی به لایه بعدی میتواند منتقل شود. این توابع، یک سطح از پیچیدگی را اضافه میکنند که شبکه را برای یادگیری از داده و تصمیمگیری بر مبنای جزییات، توانمند میسازد.
یادگیری عمیق چگونه کار میکند؟
یادگیری عمیق، از استخراج شاخص برای شناسایی شاخصها و ویژگیهای مشابه دادههای با یک برچسب یکسان استفاده کرده و سپس از مرزهای تصمیمگیری برای تعیین اینکه کدام شاخصها با دقت بالا هر برچسب را مشخص میکند، استفاده میکنند. در مساله کلاسبندی سگها و گربهها، مدلهای یادگیری عمیق اطلاعاتی همچون چشمها، صورت و شکل بدن را استخراج کرده و آنها را به دو کلاس تقسیم میکنند.
مدل یادگیری عمیق، شامل شبکههای عصبی عمیق میشود. یک شبکه عصبی ساده، دارای یک لایه ورودی، یک لایه مخفی و یک لایه خروجی است. مدلهای یادگیری عمیق، شامل چندین لایه مخفی هستند که با این لایههای اضافی، امکان بهبود دقت مدل وجود خواهد داشت.
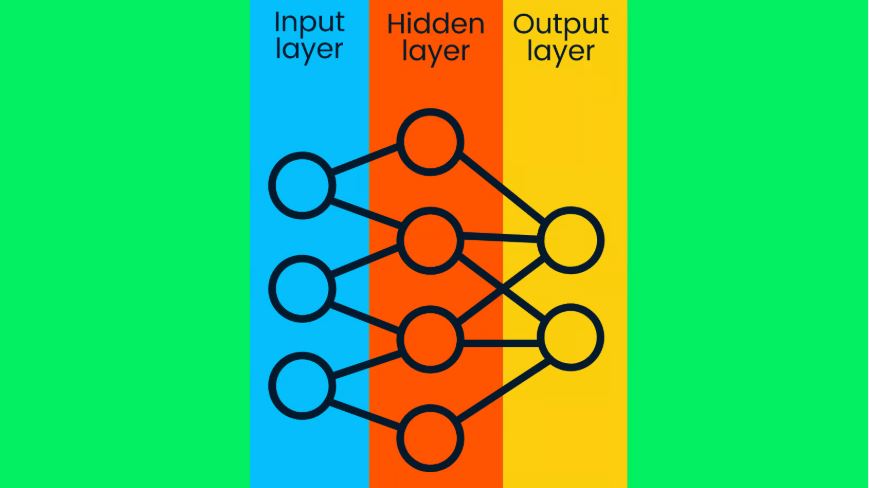
شکل ۲- شبکه عصبی ساده
لایه ورودی حاوی داده خام است و این لایه داده را به گرههای لایههای مخفی منتقل میکند. گرههای لایههای مخفی، نقاط داده را بر اساس اطلاعات هدف کلی کلاسبندی میکنند و به ورود به هر لایه بعدی، دامنه این مقدار هدف کوچکتر و باریکتر میشود تا بتواند فرضیات دقیقتری تولید کند. لایه خروجی از اطلاعات لایههای مخفی برای انتخاب محتملترین برچسب، استفاده میکند. در مساله ما، این کار، پیشبینی درست تصویر یک سگ نسبت به یک گربه با دقت بالا است.
هوش مصنوعی در مقابل یادگیری عمیق
اجازه دهید تا یکی از سوالاتی که بسیار بر روی اینترنت رایج است را پاسخ دهیم: آیا یادگیری عمیق به نوعی هوش مصنوعی است؟ پاسخ کوتاه، بله است. یادگیری عمیق یک زیرمجموعه از یادگیری ماشین است و یادگیری ماشین نیز یک زیرمجموعه از هوش مصنوعی یا AI است.
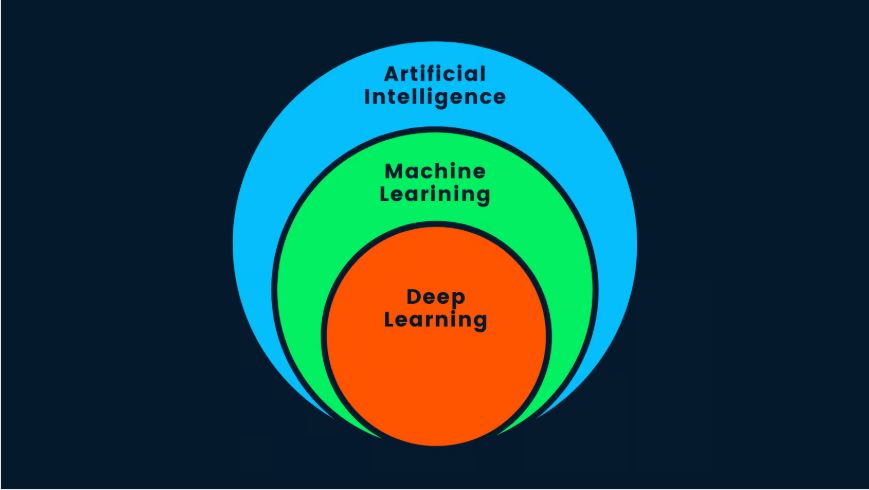
شکل ۳- AI در مقابل ML (یادگیری ماشین – Machine Learning) در مقابل DL (یادگیری عمیق – Deep Learning)
هوش مصنوعی، مفهومی است که بر پایه آن، ماشینهای هوشمند برای تقلید از رفتار انسان یا حتی فراتر رفتن از هوش انسانی، ساخته میشوند. AI از روشهای یادگیری ماشین و یادگیری عمیق برای تکمیل کارها و فعالیتهای انسان بهره میبرد. به اختصار میتوان گفت، AI، یادگیری عمیق است همانطور که این روش به نوعی پیشرفتهترین الگوریتم با قابلیت تصمیمگیری هوشمند است.
یادگیری عمیق برای چه مواردی استفاده میشود؟
اخیراً، دنیای فناوری شاهد هجوم کاربردهای مرتبط با هوش مصنوعی بوده است و این موارد همگی توسط مدلهای یادگیری عمیق، قدرت یافتهاند. کاربردهای هوش مصنوعی شامل محدوده وسیعی از سیستمهای توصیه فیلمها بر روی شبکه Netflix تا سیستمهای مدیریت کالای Amazon میشوند.
در این بخش، میخواهیم درباره برخی از مهمترین کاربردهای ساخته شده توسط یادگیری عمیق بیشتر بدانیم. این مساله به کمک میکند تا قابلیتها و پتانسیلهای شبکههای عمیق عصبی را بهتر درک کنیم.
بینایی ماشین
بینایی ماشین (Computer Vision – CV) در خودروهای خودران برای تشخیص اشیاء و جلوگیری از برخورد با موانع استفاده میشود. همچنین از آن برای تشخیص چهره، تخمین موقعیت و زاویه اشیاء یا افراد، کلاسبندی تصاویر و تشخیص ناهنجاری نیز استفاده میشود.

شکل ۴- تشیخص چهره
تشخیص گفتار اتوماتیک
تشخیص گفتار اتوماتیک (Automatic Speech Recognition – ASR) توسط میلیاردها انسان در سراسر دنیا استفاده میشود. این فناوری در تلفنهای همراه ما وجود دارد و به طور معمول با گفتن عباراتی همچون “Hey, Google” یا “Hi, Siri” فعال میشود. چنین کاربردهای صوتی در تبدیل متن به گفتار، کلاسبندی صوتی و تشخیص فعالیت صوتی نیز استفاده میشود.

شکل ۵- تشخیص الگوی گفتار
هوش مصنوعی مولد
AI مولّد (Generative AI)، شاهد رشد عظیمی در تقاضا بوده است. با تازگی CryptoPunk که یک کلکسیون هنری بر پایه هوش مصنوعی مولّد است به ارزش ۱ میلیون دلار فروخته شده است. این اثر توسط مدلهای یادگیری عمیق تولید شده است. معرفی مدل GPT-4 توسط کمپانی OpenAI، حوزه تولید متن را توسط ابزار معروف خود، ChatGPT، دچار انقلاب عظیمی کرده است. در حال حاضر، شما میتوانید مدلها را برای نوشتن یک رمان کامل یا حتی نوشتن کد برای پروژههای علوم داده خود، آموزش دهید.

شکل ۶- هنر مولّد
ترجمه
ترجمه بوسیله یادگیری عمیق، به ترجمه زبانی محدود نمیشود، همانطور که الان میتوانیم تصاویر را به کمک OCR به متن ترجمه کنیم یا متن را توسط GauGAN2 معرفی شده توسط کمپانی NVIDIA، به تصاویر ترجمه کنیم.
شکل ۷- ترجمه زبانی
پیشبینی سریهای زمانی
پیشبینی سریهای زمانی برای پیشبینی سقوطهای بازار مالی، قیمتهای سهام و تغییرات در آب و هوا، استفاده میشود. بخش مالی بر پایه حدس و گمان و تطابقسنجیهای آتی میتواند دوام بیاورد. یادگیری عمیق و مدلهای سریهای زمانی از انسان در تشخیص الگوها بهتر هستند و بنابراین در این صنعت و صنایع مشابه، ابزار تعیین کننده و کلیدی هستند.

شکل ۸- پیشبینی سریهای زمانی
اتوماسین
یادگیری عمیق برای خودکار کردن (اتوماسیون) فعالیتها و کارها نیز به کار میرود. به طور مثال، آموزش رباتها برای مدیریت انبارهای کالا، یک نمونه از این کاربرد است. معروفترین کاربرد، بازی کردن بازیهای ویدئویی و بهتر شدن در حل پازلها است. اخیرا، محصول Dota AI از کمپانی OpenAI، تیم حرفهای OG را در این زمینه شکست داده است که دنیا را شگفت زده کرده است زیرا انتظار آن نمیرفت که تمامی ۵ ربات مجازی آن، از قهرمانان در سطح جهانی، پیش بگیرند.

شکل ۹- بازوی رباتیک که توسط یادگیری تقویتی، توامند میشود
بازخورد مشتری
یادگیری عمیق برای بررسی بازخوردها و شکایات مشتریان نیز به کار میرود. این فناوری در هر سامانه ربات چت (chatbot) برای ارائه خدمات مشتریان به صورت یکپارچه وجود دارد.

شکل ۱۰- بازخورد مشتریان
زیست پزشکی
شاخه زیست پزشکی (Biomedical)، بیش از همه از معرفی یادگیری عمیق، بهره برده است. یادگیری عمیق در تشخیص پزشکی زیستی برای تشخیص سرطان، ساختن مسیر درمانی پایدار، تشخیص ناهنجاری در تصاویر اشعه ایکس سینه و در کمک رسانی به تجهیزات پزشکی به کار میرود.

شکل ۱۱- تحلیل دنباله DNA
مدلهای یادگیری عمیق
بیایید درباره انواع مختلف مدلهای یادگیری عمیق و نحوه کارکرد آنها، بیشتر بدانیم.
یادگیری با ناظر
یادگیری با ناظر از دادههای برچسب گذاری شده برای آموزش مدلها به منظور کلاسبندی داده یا پیشبینی مقادیر، استفاده میکند. مجموعه داده شامل شاخصها و برچسبهای هدف میشود که به الگوریتم امکان یادگیری در طول زمان را با حداقل کردن تابع هزینه بین مقادیر پیشبینی شده و برچسبهای واقعی، را میدهد. یادگیری با ناظر میتواند به دو دسته مسالههای کلاسبندی و مسالههای رگرسیون، تقسیم شود.
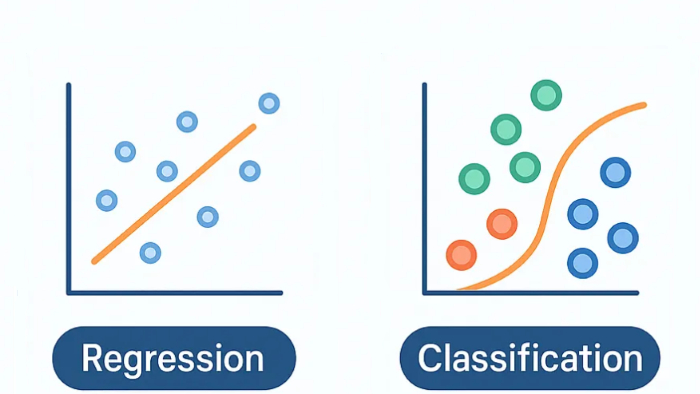
کلاسبندی
الگوریتم کلاسبندی، مجموعه داده را به گروهها (categories) مختلف بر اساس شاخصهای استخراج شده تقسیم میکند. مدلهای مشهور یادگیری عمیق، ResNet50 برای کلاسبندی تصاویر و BERT (مدل زبانی – language model) برای کلاسبندی متون هستند.
شکل ۱۲- کلاسبندی
رگرسیون
به جای تقسیم مجموعه داده به گروهها، مدل رگرسیون از رابطه بین ورودی و خروجی برای پیشبینی نتیجه، یادگیری را انجام میدهد. مدلهای رگرسیون، معمولا برای تحلیل پیشگویانه، پیشبینی وضع هوا و پیشبینی عملکرد بازار سهام استفاده میشوند. LSTM و RNN، مدلهای معروف رگرسیون با یادگیری عمیق هستند.

شکل ۱۳- رگرسیون خطی
یادگیری بدون ناظر
الگوریتمهای یادگیری بدون ناظر، الگوی درون یک مجموعه داده بدون برچسب را یار میگیرند و از آن خوشه میسازند. مدلهای یادگیری عمیق میتوانند الگوهای مخفی را بدون دخالت انسان یاد بگیرند و معمولا این مدلها در موتورهای توصیهگر (recommendation engines) استفاده میشوند.
یادگیری بدون ناظر، برای گروهبندی گونههای مختلف، تصاویر پزشکی و تحقیقات بازار استفاده میشوند. رایجترین مدل یادگیری عمیق برای خوشهبندی، الگوریتم خوشهبندی عمیقاً تعبیه شده (deep embedded) است.
شکل ۱۴- خوشهبندی داده
یادگیری تقویتی
یادگیری تقویتی (Reinforcement Learning – RL) یک روش یادگیری ماشین است که در آن عاملها (agents) رفتارهای مختلف را از محیط یاد میگیرند. این عامل، به صورت تصادفی کارهایی انجام میدهد و در ازای آن پاداش میگیرد. عامل یاد میگیرد که با سعی و خطا در یک محیط پیچیده، بدون دخالت انسان، به اهداف مورد نظر برسد.
درست مشابه یک کودک که با تشویق والدین خود، راه رفتن را میآموزد، RL نیز یاد میگیرد که برخی از کارها را با حداکثر کردن پاداش دریافتی، انجام دهد و این وظیفه طراح است که رویکرد پاداشدهی را تعیین کند. اخیراً، RL در اتوماسیون بسیار تقاضا داشته است زیرا پیشرفتهای مهمی در رباتیک، خودروهای خودران، شکست افراد حرفهای در برخی بازیها توسط ماشین و فرود موفقیتآمیز موشکها روی سطح زمین پس از برخواست، رخ داده است.
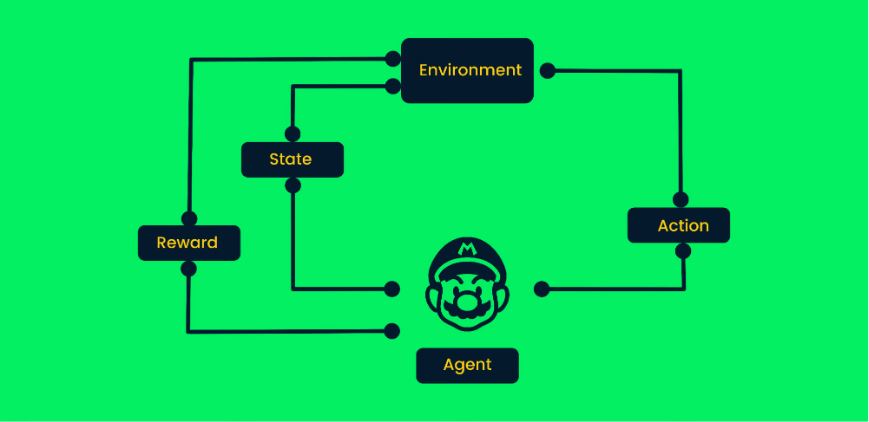
شکل ۱۵- ساختار یادگیری تقویتی
بیاید بازی Mario را به عنوان یک مثال در نظر بگیریم:
– در شروع کار، عامل (کاراکتر Mario)، از محیط حالت صفر را دریافت میکند.
– بر اساس این حالت، یک عامل، کاری را انجام میدهد، در مساله ما، Mario به سمت راست حرکت میکند.
– اکنون، حالت عامل عوض شده است و کاراکتر در یک فریم جدید قرار دارد.
– عامل یک پاداش دریافت میکند همانطور که با حرکت به سمت راست کاراکتر از بین نمیرود. هدف اصلی ما، حداکثرسازی پاداش است.
عامل این حلقه انجام کار و گرفتن پاداش را تا جایی انجام میدهد که به مرحله آخر برسد یا اینکه از بین برود.
شبکههای تخاصمی مولّد
شبکههای تخاصمی مولّد (Generative Adversarial Networks – GAN) از دو شبکه عصبی استفاده میکنند و با هم نمونههای سنتزی (مصنوعی) از داده اصلی را ایجاد میکنند. GANها در سالهای اخیر بسیار شهرت یافتهاند که به دلیل توانایی تقلید آنها از برخی هنرمندان بزرگ در تولید شاهکارهای هنری است. آنها به طور گسترده در تولید هنر تصنّعی، ویدئو، موسیقی و متون استفاده میشوند.
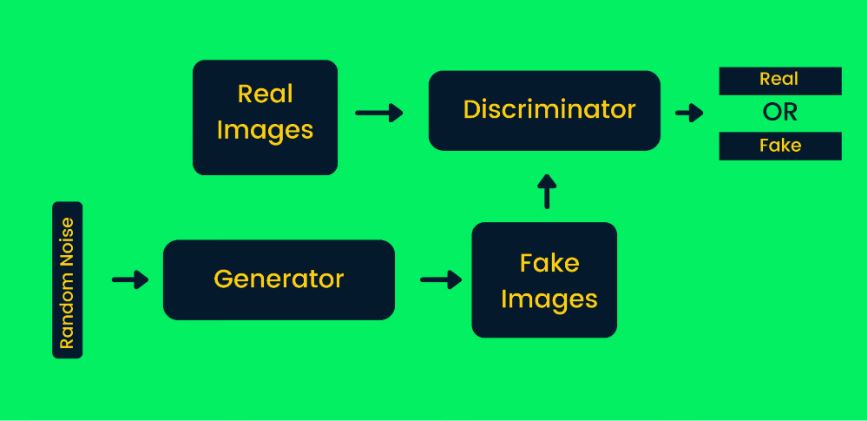
شکل ۱۶- ساختار شبکه تخاصمی مولّد
چگونه GAN در تولید تصویر مصنوعی کار میکند؟
در ابتدا، شبکه مولّد، نویز تصادفی را به عنوان ورودی دریافت کرده و تصاویر غیرواقعی یا به نوعی تقلبی ایجاد میکند.
تصاویر تولید شده و اصلی به تمایزکننده (discriminator) وارد میشوند.
تمایزکننده، تصمیم میگیرد که تصویر تولید شده واقعی است یا خیر. این کار با محاسبه احتمالات بین صفر و یک انجام میشود که صفر به معنی یک تصویر غیرواقعی و یک به معنای تصویر واقعی و اصیل است.
معماری GAN شامل دو حلقه بازخورد میشود. تمایزکننده در حلقه بازخورد تصاویر واقعی است، در حالیکه، مولّد در حقله بازخورد با تمایزکننده است. این دو عامل به صورت هماهنگ برای تولید تصاویر واقعیتر کار میکنند.
شبکه عصبی گراف
یک گراف، ساختار دادهای است که شامل یالها (edges) و گرهها (vertices) میشود. یالها میتوانند در صورتیکه وابستگی جهتدار بین گرهها وجود داشته باشد، جهتدار (directed) باشند که به گرافهای جهتدار شهرت دارند. دایرههای سبز رنگ در شکل زیر، گرهها هستند و فلشهای جهتدار، یالها را نمایش میدهند. 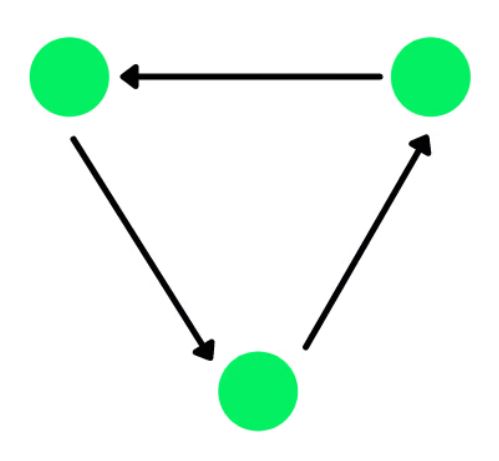
شکل ۱۷- یک گراف جهتدار
یک شبکه عصبی گراف (GNN)، نوعی از معماری یادگیری عمیق است که به طور مستقیم بر روی ساختارهای گراف عمل میکند. GNNها در تحلیل مجموعه دادههای عظیم، سیستمهای توصیهگر و بینایی ماشین به کار میروند.

شکل ۱۸- یک شبکه گراف
آنها همچنین برای کلاسبندی گرهها، پیشبینی مسیر ارتباطی و خوشهبندی استفاده میشوند. در برخی موارد، شبکههای عصبی گراف، بهتر از شبکههای عصبی کانولوشن عمل کردهاند، مثلا در تشخیص اشیاء و پیشبینی روابط معنایی.
پردازش زبان طبیعی
پردازش زبان طبیعی (Natural Language Processing – NLP)، از فناوری یادگیری عمیق برای کمک به رایانهها در یادگیری زبان طبیعی انسان، به کار میرود. NLP از یادگیری عمیق برای خواندن، رمزگشایی کردن و فهم زبان انسان استفاده میکند. این روش به طور گسترده برای پردازش گفتار، متن و تصاویر استفاده میشود. معرفی یادگیری انتقالی (transfer learning)، NLP را به سطح بالاتری برده است همچنان که اکنون قادر به تنظیم دقیق مدل با تعداد نمونههای اندک هستیم برای اینکه به قدرت عملکرد عالی نایل شویم.

شکل ۱۹- زیرگروههای NLP
NLP میتواند به چندین شاخه تقسیم شود:
– ترجمه (translation): ترجمه زبانها، ساختار مولکولی و معادلات ریاضی
– خلاصهسازی (summarization): خلاصه کردن بخشهای عظیم متون به چند خط با حفظ اطلاعات کلیدی
– کلاسبندی (classification):تقسیم متن به گروههای مختلف
– تولید (generation): تولید متن از متن که برای تولید یک متن کامل از تنها یک خط نوشته قابل استفاده است
– محاورهای (conversional): دستیار مجازی، نگهداری دانش مرتبط با مکالمات قبلی و تقلید از محاوره بین انسانها
– پاسخدهی سوالات (answering questions): AI بوسیله دادههای سوال و جواب (Q&A)، سوالات را جواب میدهد
– استخراج شاخص (feature extraction): تشخیص الگوها در متن یا استخراج اطلاعات همچون تشخیص نام افراد یا اشیاء و بخشی از گفتار
– تشابهات جملهای (sentence similarities): ارزیابی تشابهات بین متون مختلف
– تبدیل متن به گفتار (text to speech): تبدیل متن به گفتار صوتی
– تشخیص گفتار خودکار (automatic speech recognition): فهم آواهای مختلف و تبدیل آنها به متن
– تشخیص کاراکتر نوری (optical character recognition): استخراج داده متنی از تصاویر
نگاهی عمیقتر به مفاهیم یادگیری عمیق
توابع فعالسازی
در شبکههای عصبی، توابع فعالسازی (activation functions)، مرزهای تصمیمگیری برای خروجی را تولید میکنند و به منظور بهبود عملکرد مدل به کار میروند. تابع فعالسازی، یک عبارت ریاضی است که تصمیم میگیرد که ورودی بر اساس اهمیت آن، باید از یک نرون عبور کند یا نه. همچنین، ابزار اعمال تغییرات غیرخطی را نیز برای شبکه عصبی فراهم میآورد. بدون تابع فعالسازی، شبکه عصبی یک مدل رگرسیون خطی ساده خواهد بود.
لیست زیر شامل برخی انواع توابع فعالسازی مهم است:
– Tanh
– ReLU
– Sigmoid
– Linear
– Softmax
– Swish
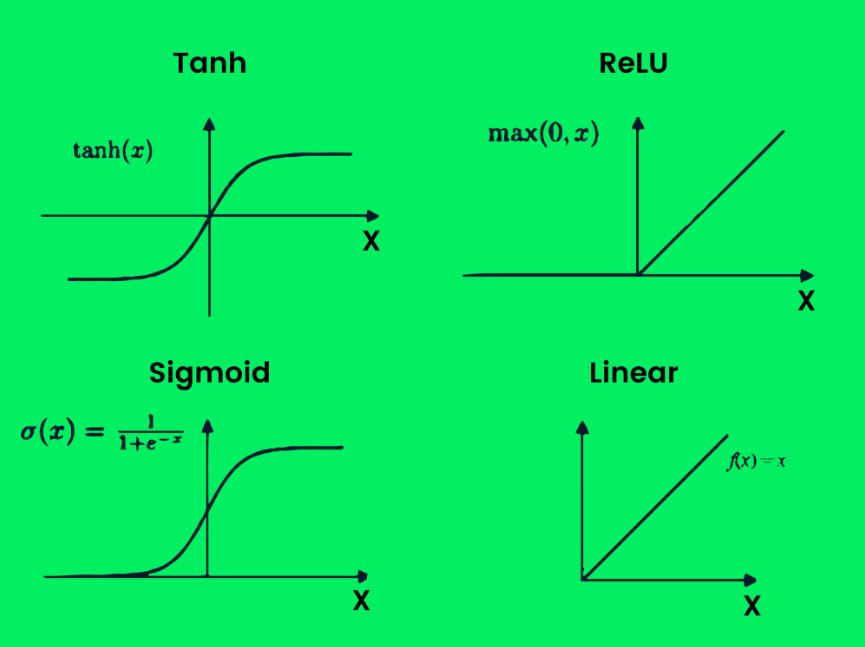
شکل ۲۰- توابع فعالسازی
این توابع، همانطور که در شکل بالا نشان داده شده است، مرزهای تصمیمگیری مختلفی ایجاد میکنند. به کمک چند لایه و توابع فعالسازی، شما میتوانید هر مساله پیچیدهای را حل کنید.
تابع هزینه
تابع هزینه (loss function)، اختلاف بین مقادیر واقعی و پیشبینی شده است. این تابع به شبکه عصبی این امکان را میدهد که عملکرد کلی مدل را رصد کند. بر اساس نوع مساله، انواع خاصی از تابع هزینه همچون تابع خطای مربع میانگین (mean squared error – MSE) استفاده میشود.
پرکاربردترین توابع هزینه در یادگیری عمیق به شرح زیر است:
– binary cross-entropy
– categorical hinge
– mean squared error
– huber
– sparse categorical cross-entropy
پس انتشار
در پیش انتشار (forwarding propagation)، شبکه عصبی را با ورودیهای تصادفی، مقداردهی اولیه میکنیم تا خروجی که خود نیز تصادفی است، تولید شود. برای بهبود عملکرد مدل، وزنها را به صورت تصادفی با استفاده از پس انتشار (back propagation)، تنظیم میکنیم. برای دنبال کردن عملکرد مدل، به تابع هزینه نیاز داریم تا مینیمم کلی (global minima) را برای حداکثر کردن دقت مدل، بیابد.
کاهش گرادیان تصادفی
کاهش گرادیان (gradient descent) برای بهینه کردن تابع هزینه با تغییر وزنهای شبکه به صورت کنترل شده و برای نیل به کمترین مقدار هزینه ممکن، استفاده میشود. حال ما یک هدف مهم داریم، اما نیاز داریم که بدانیم در جهت کاهش یا افزایش وزنها باید حرکت کنیم تا منجر به عملکرد بهتر شود. مشتق تابع هزینه، این جهت را به ما میدهد و میتوانیم از آن برای به روزرسانی وزنهای شبکه، استفاده کنیم.
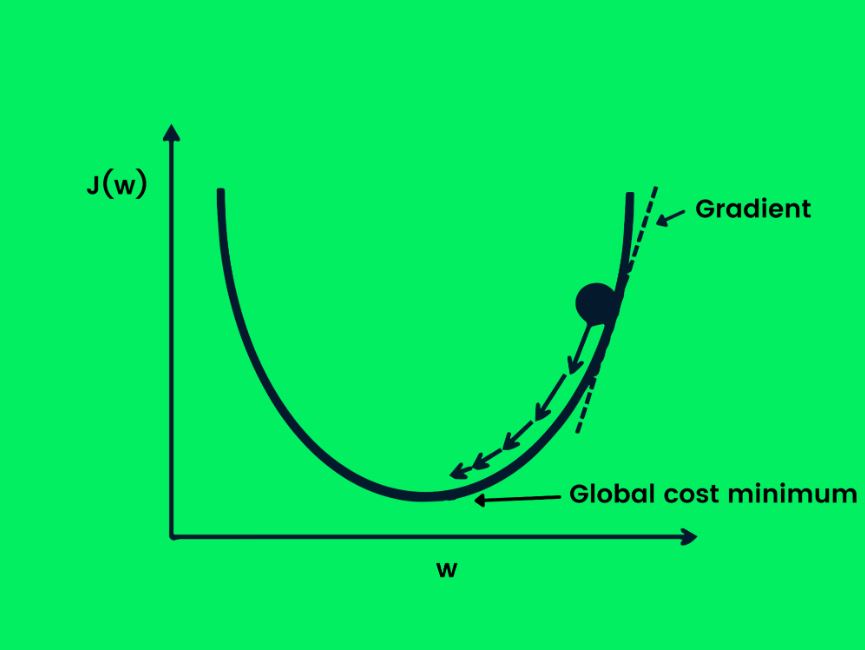
شکل ۲۱- گاهش گرادیان
معادله زیر نشان میدهد که وزنها با استفاده از کاهش گرادیان، چگونه به روز میشوند:
$$ w_{n+1} = w_n – J.w_n $$
در کاهش گرادیان تصادفی، نمونهها به جای اینکه به صورت کلی و با هم برای بهینهسازی کاهش گرادیان استفاده شوند، به دستههای (batches) جدا از هم تقسیم میشوند. این نکته از این جهت سودمند است که شما میتوانید از این طریق، حداقل تابع هزینه را سریعتر بیابید و توان محاسباتی را بهینه کنید.
ابرپارامترها
ابرپارامترها (hyperparameters)، پارامترهای قابل تنظیمی هستند که قبل از اجرای فرآیند آموزش شبکه، تنظیم میشوند. این پارامترها به طور مستقیم روی عملکرد مدل تاثیرگذار هستند و کمک میکنند تا مینیمم کلی را سریعتر بیابید.
لیست پرکاربردترین ابرپارامترها به شرح زیر ا ست:
– نرخ یادگیری (learning rate): اندازه گام هر تکرار که میتواند بین 0.1 تا 0.0001 تنظیم شود. به طور خلاصه، این پارامتر، سرعتی که مدل با آن یاد میگیرد را تعیین میکند.
– اندازه دسته (batch size): تعداد نمونههای گذر کرده از شبکه عصبی در هر لحظه است.
– تعداد دوره (number of epochs): تعداد دفعاتی که یک مدل، وزنهایش را تغییر میدهد. تعداد دوره خیلی زیاد باعث میشود که مدل بیش از حد تطبیق انجام دهد (overfit) و تعداد خیلی کم منجر به تطبیق کمتر از حد (underfit) میشود، بنابراین باید تعداد متوسطی برای این بخش در نظر بگیریم.
الگوریتمهای معروف
شبکههای عصبی در هم تنیده
شبکه عصبی در هم تنیده (Convolutional Neural Network – CNN)، یک شبکه عصبی تغذیه-مستقیم (feed-forward) است که توانایی پردازش آرایه داده ساختار یافته را دارد. این نوع شبکه، به طور گسترده در کاربردهای بینایی ماشین همچون کلاسبندی تصاویر استفاده میشود.
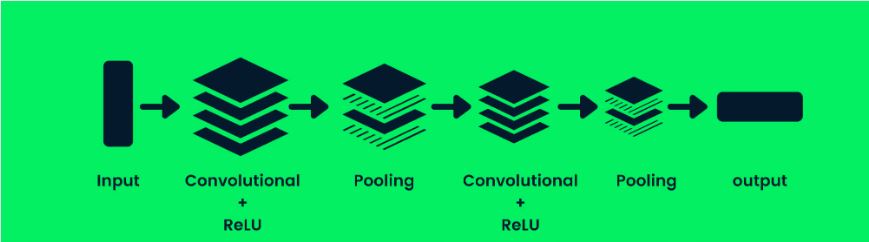
شکل ۲۲- معماری شبکه عصبی در هم تنیده
CNNها در تشخیص الگوها، خطوط و شکلها بسیار خوب عمل میکنند. یک CNN شامل یک لایه در هم پیچش یا کانولوشنال (convolutional)، یک لایه ادغام (pooling) و یک لایه خروجی (لایه به طور کامل متصل) میشود. مدلهای کلاسبندی تصویر، معمولا شامل چندین لایه کانولوشنال و به دنبال آن، چند لایه ادغام میشوند که این لایههای اضافی، دقت مدل را بالا میبرند.
شبکههای عصبی بازگشتی
شبکههای عصبی بازگشتی (Recurrent Neural Networks – RNN)، از شبکههای تغذیه مستقیم متفاوت هستند زیرا برای پیشبینی خروجی یک لایه، ارتباط بازخوردی (feedback) به ورودی وجود دارد. این ساختار کمک میکند تا شبکه برای دادههای متوالی (sequential) بهتر عمل کند همچنان که میتواند اطلاعات نمونههای قبلی را برای پیشبینی نمونههای آتی، ذخیره کند.
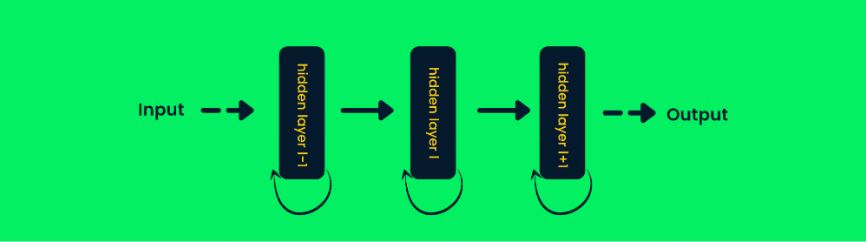
شکل ۲۳- معماری شبکه عصبی بازگشتی
در شبکههای عصبی معمول، خروجی لایههای بر اساس مقادیر ورودی فعلی محاسبه میشود ولی در RNN، خروجی بر اساس ورودیهای قبلی نیز محاسبه میشود. این نکته، RNN را در تشخیص کلمه بعدی،پیشبینی قیمتهای سهام و تشخیص ناهنجاری، بسیار توانمند میسازد.
شبکههای حافظه کوتاه-مدت بلند
شبکههای حافظه کوتاه-مدت بلند (Long Short-term Memory Networks – LSTM)، نوع پیشرفته شبکههای عصبی بازگشتی هستند که میتوانند اطلاعات بیشتری از مقادیر گذشته در خود حفظ کنند. این باعث میشود که مشکل حذف یا پریدن گرادیانها که در RNN ساده وجود دارد، حل شود.
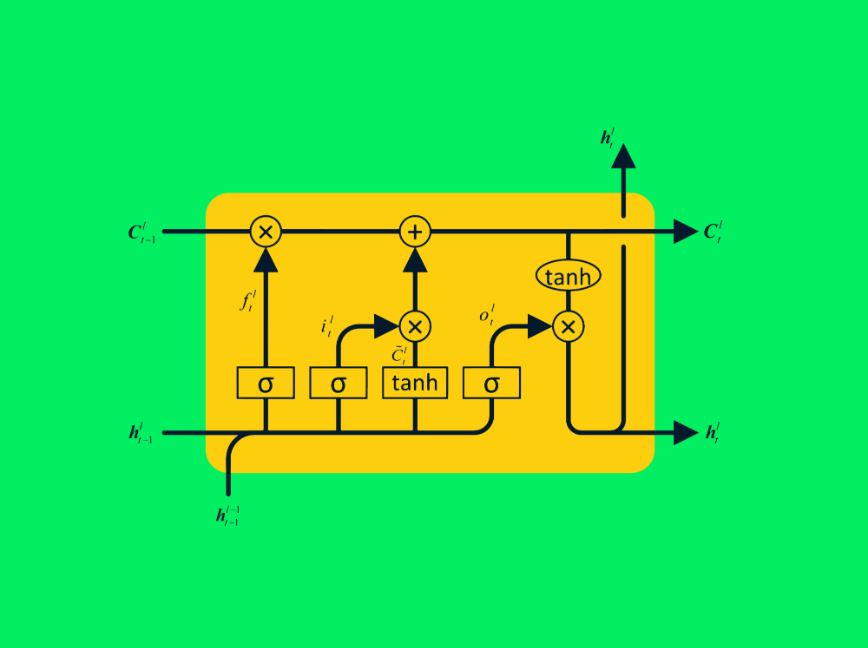
شکل ۲۴- معماری LSTM
RNN نوعی، شامل شبکههای عصبی تکرار شده با لایه tanh تکی است، در حالیکه LSTM شامل چهار لایه تعاملی است که برای پردازش دنبالههای طولانی از داده با هم در ارتباط هستند.
چارچوب یادگیری عمیق
چارچوبها و زیرساختهای مختلفی برای یادگیری عمیق وجود دارد، همچون MxNet, CNTK و Caffe2 اما در اینجا به مشهورترین چارچوبهای موجود اشاره میکنیم:
Tensorflow
Tensorflow یا TF، یک کتابخانه منبع-باز است که برای کاربردهای یادگیری عمیق در پایتون استفاده میشود. این بسته شامل تمام ابزارهای لازم برای انجام آزمایش و توسعه محصولات AI است. همچنین از سختافزارهای CPU, GPU و TPU برای آموزش مدلهای پیچیده پشتیبانی میکند. TF از ابتدا توسط تیم هوش مصنوعی گوگل برای استفاده داخلی توسعه یافت و در حال حاضر در دسترس عموم قرار دارد.
واسط کاربری TF برای کاربردهای مبتنی بر مرورگر (browser)، ابزارهای موبایل در دسترس است و نسخه گسترش یافته آن، TensorFlow Extended برای تولید مناسب است. TF در حال حاضر یک استاندارد صنعتی به حساب میآید و در هر دو حوزه تحقیقات آکادمیک و به کارگیری مدلهای یادگیری عمیق در فرآیند تولید استفاده میشود.
همچنین در کنار آن، Tensorboard نیز ارائه شده است که یک داشبورد با توانایی تحلیل آزمایشهای یادگیری ماشین است. اخیراً، توسعهدهندگان TF، کتابخانه Keras را در این چارچوب ادغام کردهاند که برای توسعه شبکههای عصبی عمیق شهرت دارد.
Keras
Keras یک چارچوب شبکه عصبی است که به زبان پایتون نوشته شده و توانایی اجرا بر روی چارچوبهای دیگر همچون TensorFlow و Theano را دارد. Keras یک کتابخانه منبع-باز است که برای انجام آزمایشهای سریع در حوزه یادگیری عمیق توسعه یافته است و بنابراین از طریق آن میتوان به سادگی مفاهیم را به کاربردهای AI تبدیل کرد.
مستندات ارائه شده به همراه Keras بسیار ساده و قابل فهم است و واسط کاربری آن مشابه Numpy است که به شما این امکان را میدهد که آ» را در هر پروژه علوم دادهای به کار بگیرید. درست مشابه TF، چارچوب Keras نیز میتواند بر روی CPU, GPU و TPU بر اساس سختافزار در دسترس، اجرا شود.
PyTorch
PyTorch، معروفترین و سادهترین چارچوب یادگیری عمیق است. در آن از تنسور (Tensor) به جای آرایه Numpy برای انجام محاسبات عددی سریع که تقویت شده توسط GPU هستند، استفاده میشود. PyTorch بیشتر برای یادگیری عمیق و توسعه مدلهای یادگیری ماشین استفاده میشود.
محققان حوزه آکادمیک استفاده از PyTorch را ترجیح میدهند زیرا انعطافپذیری و سادگی کاربری بالایی دارد. این ساختار به زبان ++C و پایتون نوشته شده است و همچنین به همراه شتابدهندههای GPT و TPU ارائه میشود. این ابزار به یک راهحل عالی برای مسائل یادگیری عمیق تبدیل شده است.
جمعبندی
در این مقاله، تمام آنچه که یادگیری عمیق است را پوشش دادیم و برخی اصول آن را نیز بررسی کردیم از جمله اینکه چگونه کار میکند و کاربردهای آن چیست. همچنین، چگونگی عملکرد شبکههای عصبی عمیق و انواع مختلف مدلهای یادگیری عمیق را نیز بررسی کردیم. در نهایت، با برخی چارچوبهای مشهور یادگیری عمیق آشنا شدیم.
منبع: https://www.datacamp.com